
Welcome to the 7th edition of the EDB Engineering Newsletter! Where we share happenings in the data world that the team has enjoyed discussing, as well as other news about what the EDB Engineering team is up to.
Analysis we're following
A Series on CRDTs by Joe Hellerstein

Joe Hellerstein of UC Berkeley wrote a series of posts on Conflict-free Replicated Data Types (CRDTs).
The Dawn Of Nvidia's Technology

After two recently published books on the history of Nvidia, David Rosenthal, employee #4 and former chief scientist at Nvidia, wrote a more detailed technical explanation for two early innovations at Nvidia: the imaging model and the I/O architecture.
https://blog.dshr.org/2025/05/the-dawn-of-nvidias-technology.html
The Coming AI Revolution in Distributed Systems

Cheng Huang, tech lead at Azure Storage, wrote about how GitHub Copilot Agent was able to analyze Azure Storage’s production code and develop a TLA+ model for the production code that, after running a model checker on the Copilot-generated TLA+ model, found an actual bug in production Azure Storage code.
This subtle bug had escaped detection through traditional methods, yet given Azure Storage’s scale, it would likely have manifested in production eventually.
Hillel Wayne’s response to Cheng Huang’s post was also interesting:
Right now, agents seem good at the tedious and routine parts of TLA+ and worse at the strategic and abstraction parts. But, since the routine parts are often a huge barrier to beginners, this means that LLMs have the potential to make TLA+ far, far more accessible than it previously was.
The broader sentiment here echoes recent writing by other engineers we think highly of: Steve Klabnik publishing I am disappointed in the AI discourse and Armin Ronacher publishing AI Changes Everything.
1000x Increase in AI Demand

AI demand is surging due to a shift from simple one-shot tasks to complex reasoning, which requires significantly more compute and generates far more tokens per task. Companies like OpenAI, Microsoft, and Google are leading this shift—Microsoft alone processed over 100 trillion tokens in Q1, a 5x year-over-year increase.
To meet this demand, hyperscalers are deploying around 72,000 NVIDIA GPUs per week and investing over $300 billion in data centre infrastructure, often referred to as “AI factories.” Despite improvements in model efficiency, the rapid growth in reasoning-based usage is outpacing these gains, driving an unprecedented expansion in AI infrastructure.
https://tomtunguz.com/nvda-2025-05-29/
Cloud GPU Comparison

What it says on the box.
LLM Engine Advisor

Modal published interactive benchmark results of open weight language models on open source inference engines. This is primarily interesting to organizations that choose to run these workloads themselves, organizations that (for whatever reason) are not using proprietary services like Anthropic or OpenAI.
https://modal.com/llm-almanac/
News we’re watching
Google AI Edge Gallery

Google has quietly released a new Android app that allows users to download and run open-source AI models locally on their phones. The app supports a variety of models from Hugging Face, enabling tasks like image generation, Q&A, and code editing entirely offline. This approach addresses privacy concerns and provides access without relying on cloud connectivity.
While performance depends on device hardware and model size, the app includes a “Prompt Lab” for single-turn tasks with configurable settings. It’s released as an experimental alpha under the Apache 2.0 license, and Google encourages developer feedback and contributions.
https://github.com/google-ai-edge/gallery
CloudNativePG Contributor Spotlights

Floor Drees continues a series interviewing contributors to CloudNativePG, this month included interviews with:
The future of AI agents—and why OAuth must evolve
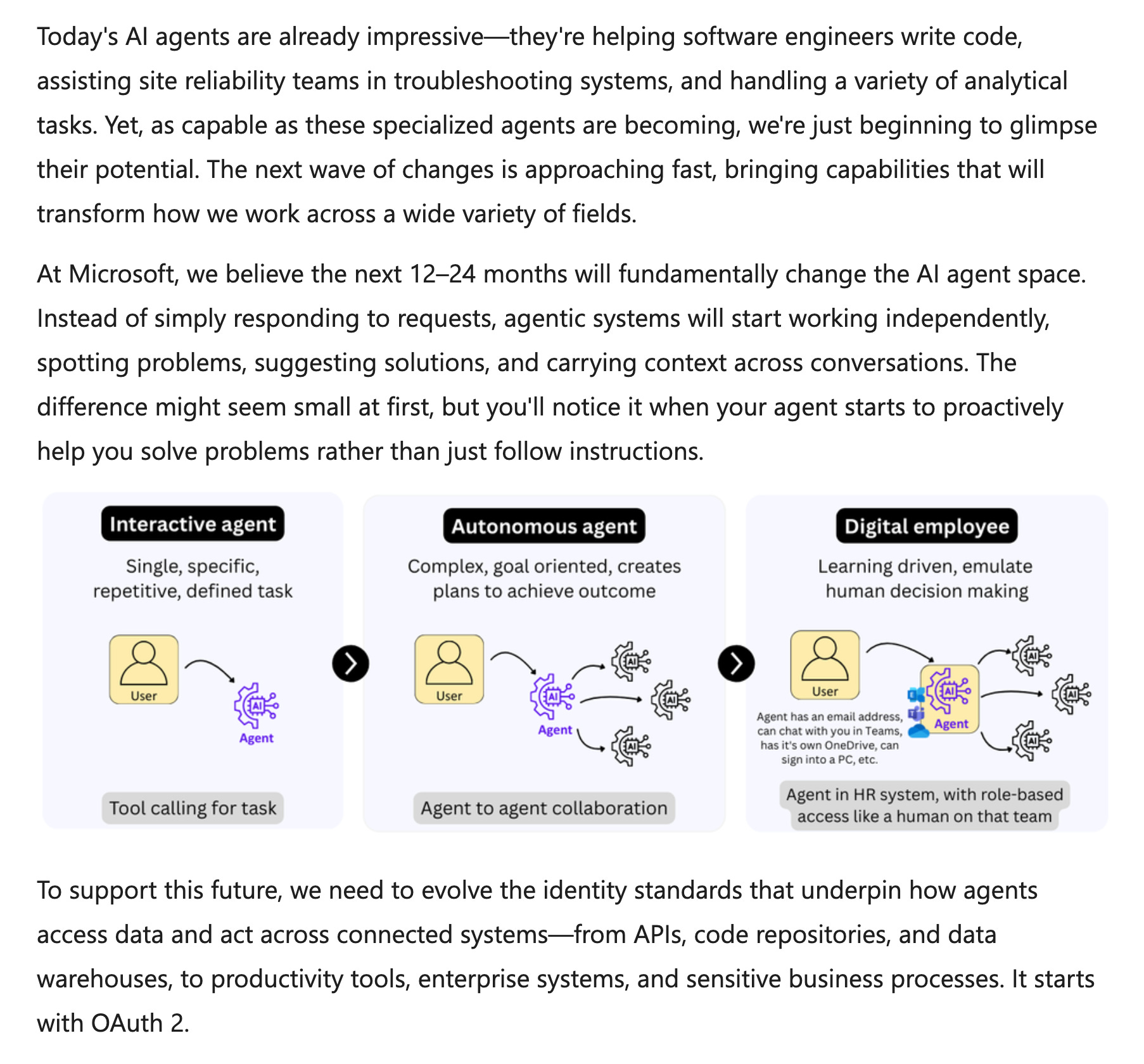
AI agents are quickly evolving from reactive tools into proactive, autonomous systems capable of carrying context, identifying issues, and executing tasks across workflows. Microsoft foresees a major shift within 12–24 months, as agents become core actors in software, marketing, compliance, and IT operations. However, today’s OAuth 2.0 standards are not built for these agentic use cases.
To support secure, scalable agent interactions, Microsoft proposes key changes: introducing Agent IDs as first-class actors, defining standalone agent permissions, ensuring transparent agent activity, enabling permission discovery, and supporting fine-grained, least-privilege access. These updates aim to future-proof identity and access frameworks for the next generation of AI-native systems.
CloudNativePG Linux Foundation Mentorship

Ying Zhu, a Master’s student at Carnegie Mellon University, was selected to work on Declarative Management of PostgreSQL FDWs for CloudNativePG as part of the Linux Foundation’s Mentorship program.
For this newsletter, Gabriele Bartolini (VP, Chief Architect, Kubernetes at EDB) writes: “As maintainers of a CNCF project, we were thrilled to learn about the Linux Foundation Mentorship Program at the recent KubeCon in London, and we’re excited to begin a three-month mentorship with Ying. This will be a valuable learning experience not only for Ying, but also for the four of us mentors. We’re committed to making the Linux Foundation Mentorship Program a recurring initiative in future terms as part of our ongoing efforts to build a more vibrant and diverse community around CloudNativePG.”
We’re excited to see what you do, Ying!
https://mentorship.lfx.linuxfoundation.org/mentee/3bf7994a-4575-4cd0-bb6f-cadf98dfc979
Ambience Healthcare's AI Platform Surpasses Clinician Performance by 27% in Medical Coding

Ambience Healthcare has introduced a new AI model for ICD-10 medical coding that outperforms physicians by 27%. Trained using OpenAI's reinforcement fine-tuning methods, the model listens to patient encounters and accurately assigns diagnostic codes, a task typically seen as time-consuming and error-prone. Validated against expert clinician benchmarks, it surpassed board-certified doctors on complex cases.
The system is designed to support—not replace—clinicians by reducing administrative workload and billing mistakes. Already deployed in institutions like Cleveland Clinic and UCSF, Ambience plans to expand the model’s capabilities across other medical workflows.
From the EDB team
Databases in the AI Trenches

Bruce Momjian spoke at PgConf Nepal 2025 about the fundamentals of large language models and integrating LLMs with PostgreSQL.
His slides are available here.
Unified Observability-Monitoring Postgres Anywhere with OpenTelemetry
Yogesh Jain spoke at PgConf Nepal 2025. The talk abstract:
PostgreSQL is widely used across cloud, Kubernetes, and bare metal environments. But how can we monitor it efficiently across all these setups without vendor lock-in or high costs? In this talk, we'll explore how OpenTelemetry helps achieve consistent and scalable observability for Postgres - no matter where it runs. We'll walk through how to collect metrics and logs, integrate them with open-source observability tools, and optimize monitoring for both performance and cost. Expect live demos and practical insights on making PostgreSQL monitoring simple, efficient, and future-ready with OpenTelemetry.
You can read more about his trip and his talk on his blog.
Improving the PostgreSQL Extensions Experience in Kubernetes with CloudNativePG
Gabriele Bartolini shared how extension management works in the popular Kubernetes operator, at the Extensions Ecosystem Mini-Summit, a series of virtual events leading up to PGConf.Dev in Montreal.
His slides are available here.
Debugging memory leaks in Postgres, heaptrack edition
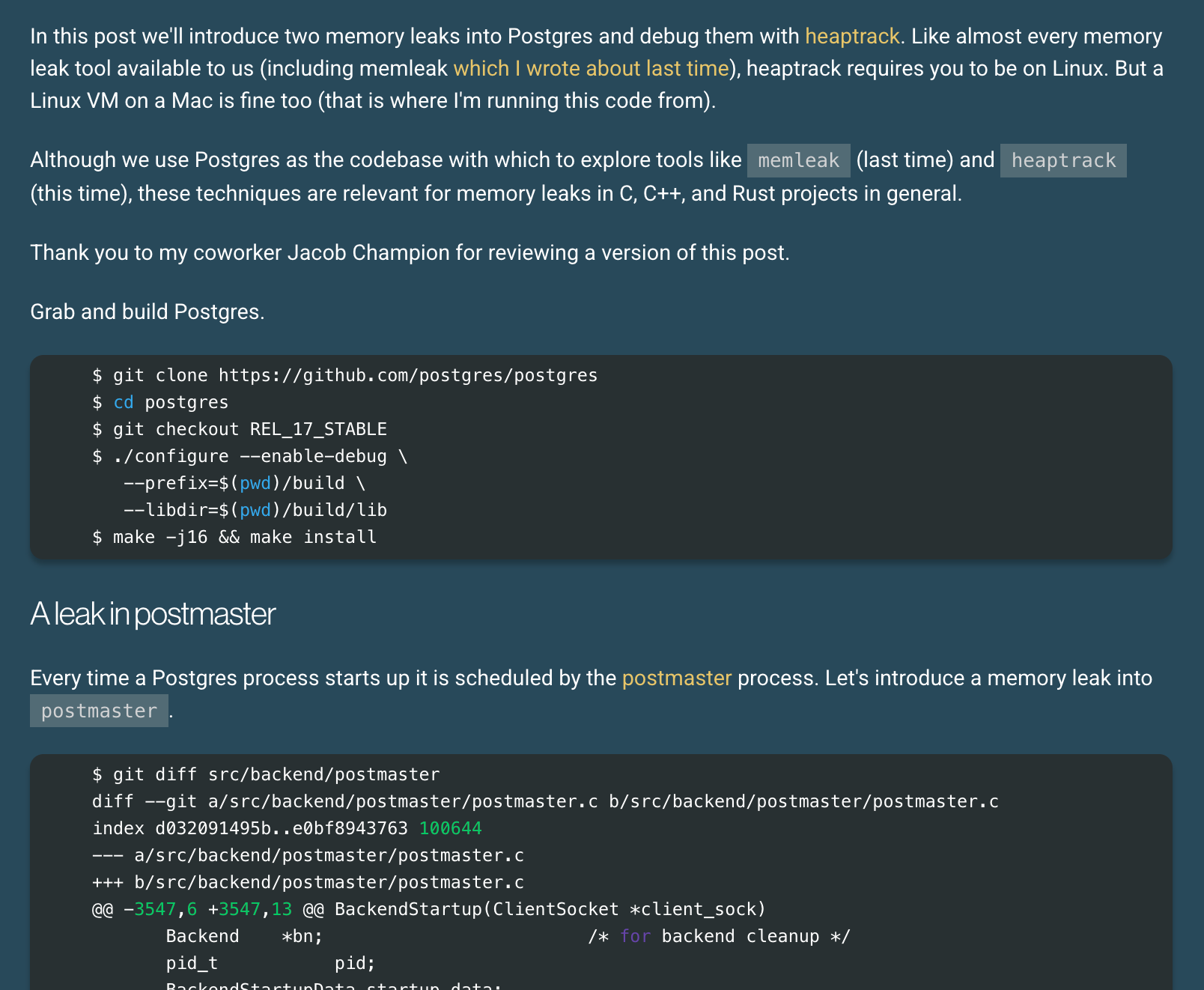
Phil Eaton wrote about debugging memory leaks in Postgres with heaptrack.
https://www.enterprisedb.com/blog/debugging-memory-leaks-postgres-heaptrack-edition
The Well-Tempered Elephant

Gianni Ciolli spoke at PGConf.DE 2025. The talk abstract:
PostgreSQL is a multi-modal database management system, thanks to features such as extensions, pluggable languages, and the ability to define data types, aggregates and operators in user space.
In this talk we combine all those elements to frame a well known real world problem as a data analysis exercise, aiming to demonstrate the power and flexibility of PostgreSQL.
We load the 48 fugues from the Well-Tempered Clavier by J.-S. Bach, note by note, into a PostgreSQL table. Then we show how custom PostgreSQL objects can be used to assist the analysis of the finest counterpoint from this masterpiece of music.
His slides are available here.
PostgreSQL Configuration File: Less is More

Lætitia Avrot spoke at PGConf.DE 2025. The talk abstract:
A cluttered PostgreSQL configuration file is a ticking time bomb. From redundant settings and unnecessary comments to lack of version control, messy configuration files often lead to wasted time and avoidable production issues.
In this talk, we’ll discuss why and how to keep your postgresql.conf file clean,
concise, and well-organized.We’ll explore practical techniques like removing defaults, avoiding duplicates, leveraging include files, and ensuring proper version control (with Git). You’ll see how a minimal, well-documented configuration file can reduce risks and improve performance, observability, and troubleshooting. To wrap up, we’ll review an example
of a clean, production-ready PostgreSQL configuration file and examine how these
practices contribute to better database management.
Her slides are available here.
From Distance to Intelligence: Evolving Your Vector Search
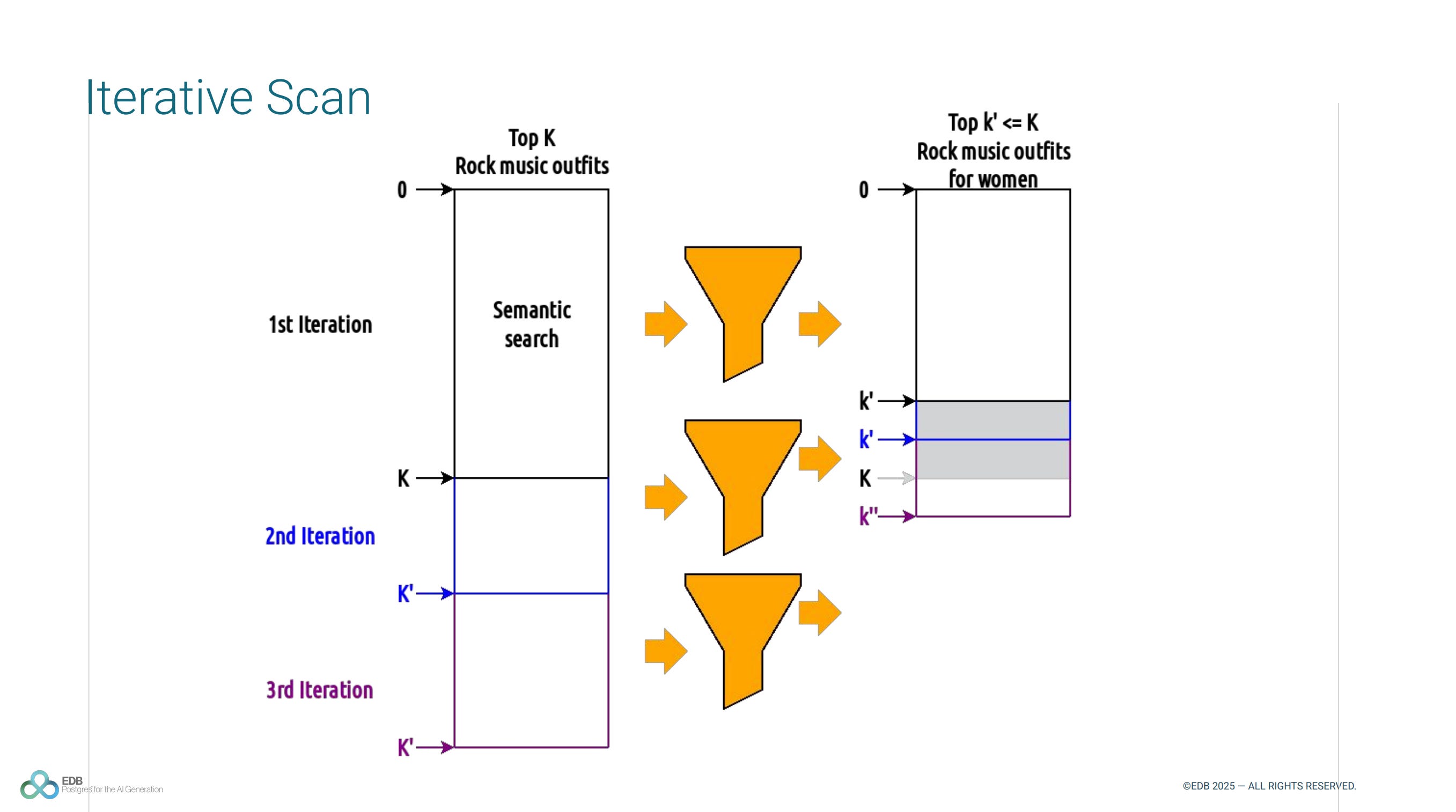
Bilge Ince & Boriss Mejias spoke at PGConf.DE 2025. The talk abstract:
Search requirements in production environments rarely fit a one-size-fits-all approach. While both full-text and vector search offer distinct advantages, each has inherent limitations. Traditional full-text search struggles with semantic understanding, falling short when users need context-aware results. Vector search emerged as a promising alternative, excelling at semantic relationships but sometimes missing exact matches or struggling to prioritize the most contextually relevant results based on vector distance alone.
As we know, PostgreSQL is a relational database that also features full-text and vector search, and therefore, offers many more possibilities beyond these two functionalities. This talk explores how to transform basic vector search implementations into sophisticated search systems, combining the strengths of multiple approaches to deliver more accurate and context-aware results.
Their slides are available here.
What is an SLRU anyway?

Álvaro Herrera spoke at PGConf.DE 2025. The talk abstract:
An important performance optimization was added to Postgres 17, which changed the way SLRUs are managed and configured. But what are exactly these SLRUs? What do they store? What exactly was changed in Postgres 17? How do we now configure them? This talk goes over these questions in detail.
His slides are available here.
Modernes SSL ideal einsetzen

Peter Eisentraut spoke at PGConf.DE 2025. The talk abstract:
Die SSL-Unterstützung in PostgreSQL ist alt und SSL selbst ist noch älter. Neue Versionen sind herausgekommen und viele neue Optionen zur Einrichtung und Konfiguration sind entwickelt worden. Darüber hinaus gibt es viele komplizierte Regelwerke, gesetzliche Bestimmungen und Sicherheitsbelange, die viele Benutzer betreffen und sich ständig ändern.
In diesem Vortrag bespreche ich, wie SSL für PostgreSQL auf eine moderne und robuste Weise eingerichtet werden kann, welche Versionen und Optionen verwendet werden sollten und welche man lieber gleich wieder vergisst, wie Protokolle und Ciphers ausgewählt werden, wie man mit Schlüsseln und Zertifikaten umgeht und wie man sich mit (einigen) regularischen Angelegenheiten auseinandersetzen kann. Außerdem werde ich betrachten, wie Verbindungs-Proxies und Pooler wie PgBouncer den SSL-Einsatz beeinträchtigen. Abschließend schauen wir uns einige neue Möglichkeiten in PostgreSQL 17 und 18 an, die den SSL-Einsatz mit PostgreSQL hoffentlich in der Zukunft effizienter und sicherer machen werden.
His slides are available here.
Extend your PostgreSQL: The world of PostgreSQL extensions

Devrim Gündüz spoke at PGConf.DE 2025 on the history and current state of developing extensions for PostgreSQL.
His slides are available here.
Memory Management and Leaks in Postgres
Phil Eaton spoke at the inaugural Postgres Extensions Day, co-located with PGConf.dev. The talk abstract:
We'll explore practical usecases for creating and switching between MemoryContext's and Linux tools like ebpf that can help us discover memory leaks. The session will be a distillation of real-world scenarios and exploration of tools that have helped find bugs in production extensions.
His slides are available here.
Rethinking PostgreSQL Performance in the Age of Monster Hardware

Lætitia Avrot spoke at PGConf.dev. The talk abstract:
In an era where single servers boast terabytes of RAM, ultra-fast SSDs, and CPUs with hundreds of threads, the conventional wisdom of horizontal scaling often feels outdated. Why distribute load across a cluster when a single machine can handle it all? This talk explores how modern hardware advancements challenge the traditional emphasis on horizontal scaling and highlight the untapped potential of vertical scaling, particularly for PostgreSQL workloads.
We’ll explore how PostgreSQL leverages today’s powerful hardware, including its interaction with the operating system, its approach to parallelism, and its handling of memory and IO. By understanding these dynamics, attendees will gain insights into how PostgreSQL can be optimized to fully exploit the capabilities of modern servers, making vertical scaling a practical and powerful approach.
Her slides are available here.
What is new in C and POSIX?

Peter Eisentraut spoke at PGConf.dev. The talk abstract:
These things might appear to move at glacial speeds, but sometimes new things do actually happen in C and POSIX, the programming language environment that PostgreSQL is built on. A new C standard and a new POSIX standard both were released in 2024. And of course there are several predecessor versions of those standards that PostgreSQL has not adopted yet.
In this presentation, I'll show how the C and POSIX standards are developed, what the state of implementation of the different versions is in different compilers and different operating systems and when they might become relevant to PostgreSQL development. I'll demonstrate some of the new features and how they could be applied to PostgreSQL source code. We'll discuss how we can apply these facilities to support ongoing themes in PostgreSQL development, such as thread-safety, improved locale support, better type safety, and better code generation.
His slides are available here.
Committer Review: An Exercise in Paranoia

Robert Haas spoke at PGConf.dev. The talk abstract:
Many people review patches on pgsql-hackers, but reviews from committers cary special weight because only a committer can execute the 'git push' command that makes someone's patch part of the official PostgreSQL source tree. But, what exactly is a committer doing when they review a patch with the intent of committing it? In this talk I'll discuss the strategies I use when reviewing and committing patches to PostgreSQL.
There is probably a fair amount of variation among committers, so just because I do something in a certain way doesn't mean that everyone else does the same, and I'm not familiar with everyone else's practices, but where I know of specific differences, I'll attempt to highlight them. Along the way, I'll try to address the question of why committers are often very cautious about committing patches even when they seem to be good and well-written patches which implement things that would definitely be useful to the project.
His slides are available here.
Getting Started with pgvector on Kubernetes Using CloudNativePG

Gabriele Bartolini wrote a tutorial on setting up pgvector within CloudNativePG.
Hacking Workshop for June 2025

Robert Haas will host the next PostgreSQL Hacking Workshop this month, featuring Masahiko Sawada.
https://rhaas.blogspot.com/2025/05/hacking-workshop-for-june-2025.html
Until next time
We hope you enjoyed this edition of the EDB Engineering Newsletter! Consider joining the PostgreSQL Hacker Mentoring Discord to get involved!
The EDB Engineering Team