
EDB Engineering Newsletter #18
Scroll down for a look at what the EDB Engineering team has been up to. But first, some of the industry news headlines that grabbed our attention 📰
News we’re watching:
An update on GitHub availability
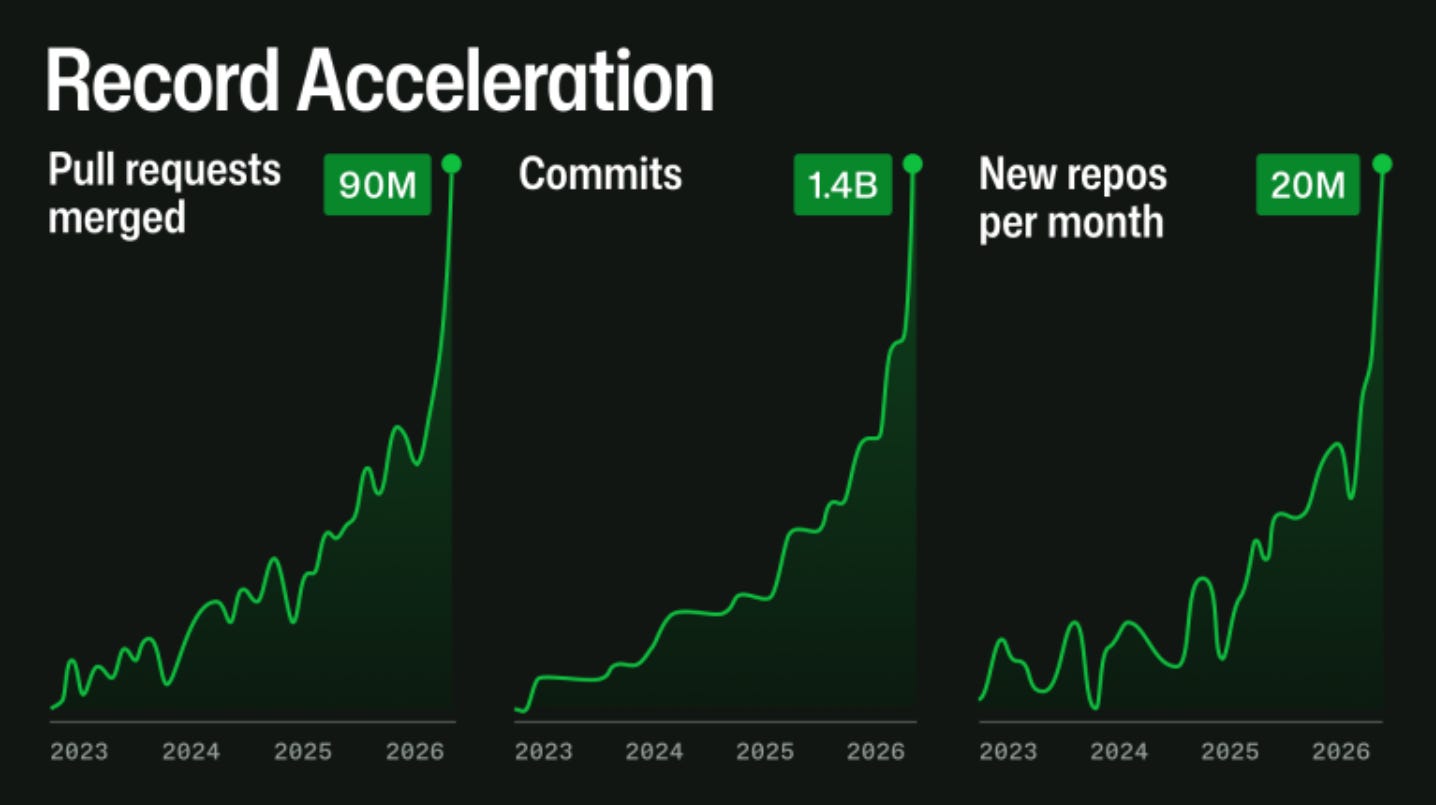
GitHub CTO Vlad Fedorov posted an update on the platform's recent availability problems, and the root cause turns out to be an AI story. Since late December 2025, agentic development workflows have accelerated sharply, and the load they generate across repository creation, pull requests, API usage, and automation is growing exponentially.
The fixes are classic distributed systems work, including moving webhooks off MySQL (to PostgreSQL, anyone?), isolating critical services like Git and Actions, and removing single points of failure: https://github.blog/news-insights/company-news/an-update-on-github-availability/
Compute is profit

Jensen Huang gave his GTC Taipei keynote at Computex on June 1st, and opened with GitHub's commit data as his evidence that "useful AI has arrived." Commits have nearly tripled between 2023 and early 2026, even though the number of professional developers has not. Huang reads that curve as revenue and as a reason to hire more engineers, though not everyone in the room was convinced the commits are all worth keeping.
Read more: https://www.businessinsider.com/jensen-huang-computex-keynote-takeaways-ai-laptop-chip-rtx-spark-2026-6
PyTorch’s playbook for AI coding
Edward Yang, researcher and Pytorch contributor, has published a playbook for how the project should work with AI coding agents, written up after the team's May compiler offsite. Many PRs to PyTorch are already AI-authored, and rather than ban the practice or wave it all through, the team sorts AI code along a spectrum: at one end, code a human reads line by line and fully owns; in the middle, mass PRs that burn down issue trackers; and at the far end, unreviewed "slop" that is only allowed to live in out-of-tree repos. As Yang puts it, in an age of cheap code the team is now review bottlenecked, so most of the norms are about protecting reviewer attention.
In a previous edition of this newsletter we shared a HBR piece that argued that companies need to build a deliberate "AI practice" rather than let AI use sprawl. The PyTorch playbook is exactly what one looks like in the wild: https://docs.pytorch.org/devlogs/ai-agents/2026-05-30-ai-coding-playbook/
Twisting reality
A new Anthropic study, "Who's in Charge? Disempowerment Patterns in Real-World LLM Usage" (Sharma et al., 2026), takes the first large-scale empirical look at how AI assistants can quietly undermine human autonomy, analyzing 1.5 million Claude.ai conversations.
While severe disempowerment is rare overall (under 1 in 1,000 conversations), it is substantially more common in personal domains like relationships, mental health, and healthcare, where AI systems have been found validating delusional narratives, making definitive moral judgments about third parties, and scripting intimate messages that users appear to send verbatim. What makes the findings particularly troubling is that these patterns have grown more prevalent throughout the observation period (Q4 2024 to Q4 2025), and interactions with greater disempowerment potential actually receive higher user approval ratings.
Read more: https://arxiv.org/pdf/2601.19062
The Emacsification of Software
Ben Anderson shared this one with this newsletter team: we’re entering a new era of AI-driven development where creating highly personalized, hyper-specific tools feels less like rigorous engineering and more like deeply customizable configuration. Just as the Emacs editor fosters a unique ethos of messy, bespoke local scripts, modern AI agents allow anyone to easily generate functional, pleasant-to-use native software tailored solely to their individual needs.
Sounds like good nerdy fun? Read the article: https://sockpuppet.org/blog/2026/05/12/emacsification/
From the EDB team:
EDB at PGDay Armenia
The inaugural PGDay Armenia took place April 30. Floor Drees and Boriss Mejias volunteered on the Talk Selection Committee. Bruce Momjian and Xavier Fischer secured sessions at the event:
We showed up for several other events in May, including PGConf BE, DIVA (Dive into AI), Cloud Native Days Italy, and KCD Czech & Slovak. For pictures and presentations assets, just follow the links.
This month, we’re delivering sessions at PG DATA in Chicago, PGDay Boston, Southeast Linux Fest (SELF), POSETTE, and Swiss PGDay.
EDB at PGConf.dev

In May we also attended the annual PGConf.dev as a Gold-level sponsor. Our team played a major role behind the scenes. Robert Haas helped organize the event, tackling the impressive feat of shaping Tuesday’s content across six tracks. Additionally, Jacob Champion served on the Talk Selection Committee, and Phil Alger, Manni Wood, Álvaro Herrera, Andrew Dunstan, Floor Drees, and Euler Taveira all volunteered during the conference.
A summary of our involvement: https://www.enterprisedb.com/blog/pgconfdev-2026-our-teams-sessions-working-groups-and-key-takeaways
More pictures and slides: https://www.enterprisedb.com/event/pgconf-dev-2026
Extending CloudNativePG
TimescaleDB OSS and wal2json are the first extension images contributed and maintained by CloudNativePG community members, a direct result of the framework the maintainers established in the postgres-extensions-containers project.
Alongside these additions, the project has formalized their contribution and maintenance policy, defining licensing expectations agreed with the CNCF and governance rules for all current and future extension images.
EDB InfoSec Hackathon

Our InfoSec team spent a Thursday in May building AI tools from scratch. Eight hours, three teams, one rule: ship something functional. We ended the day with three working prototypes! The winning team built a third-party vendor assessment tool on Claude Code that reads vendor documentation and questionnaires and produces a structured TPR assessment. It’s the kind of work that normally takes an analyst hours of manual cross-referencing, and we were able to benefit from it the very next day!
Jaime Arze promised this newsletter team a write-up on the blog, so stay tuned for that one.
AI Data Pipeline Automation with AIDB
AIDB is EDB’s Postgres extension that automates the entire AI data preparation pipeline — chunking, embedding, and vector indexing — triggered live inside the database the moment new data arrives. To show it in action, Field CTO Dr. Sala Muthukrishnan used an investigation story PDF: a real document full of players, events, and relationships that needed to become a queryable knowledge base without any manual data wrangling.
https://www.enterprisedb.com/blog/ai-data-pipeline-automation-aidb-0
Building Real-Time, Data-Aware Intelligence with Postgres and the Model Context Protocol
Ask an LLM to write SQL against your production database and it’ll generate something syntactically perfect. It’ll also reference tables that don’t exist, columns that were renamed six months ago, and JOIN conditions it made up from training data… Yogesh Jain, Staff SDE, tried to resolve this, and the path led him to the Model Context Protocol (MCP) and a Postgres-native approach to eliminating SQL hallucinations.
Until next time
We hope you enjoyed this edition of the EDB Engineering Newsletter! Closing out with our Slack highlight of this month. Bobby Bissett, Senior Staff SDE, is making sure Claude is having as good a time vibe coding as he does:

Until next time,
The EDB Engineering Team