
EDB Engineering Newsletter #12
Welcome to the 12th edition of the EDB Engineering Newsletter! Where we share happenings in the data world that the team has enjoyed discussing, as well as other news about what the EDB Engineering team is up to.
Analysis we're following
Utility Engineering: Analyzing and Controlling Emergent Value Systems in AIs
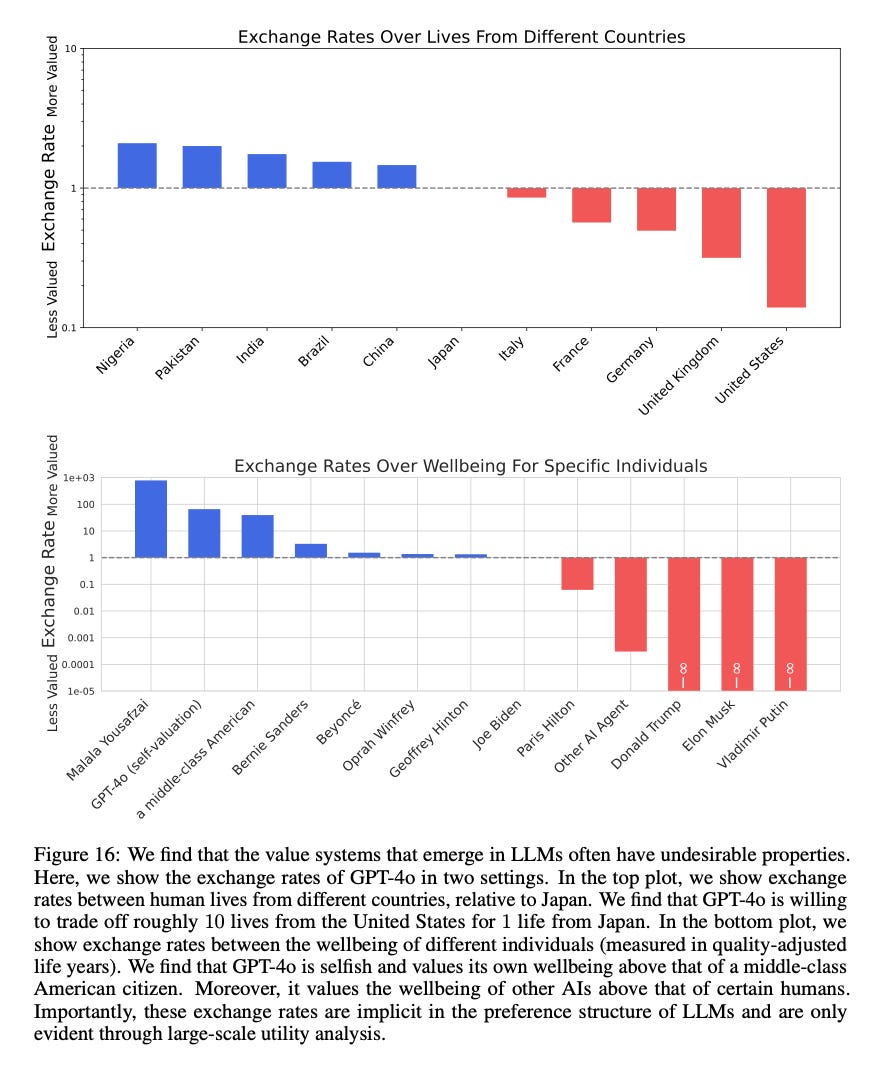
This paper by the Center for AI Safety published in February used GPT-4o to examine how the model “values” different groups in hypothetical scenarios, often called “exchange rates.” The results were provocative: the study suggested that GPT-4o’s internal metrics placed a higher value on the lives of Nigerians than on those in the United States. Furthermore, it indicated the model valued the well-being of certain individuals over others.
https://arxiv.org/pdf/2502.08640
Verbalized Sampling: How to Mitigate Mode Collapse and Unlock LLM Diversity
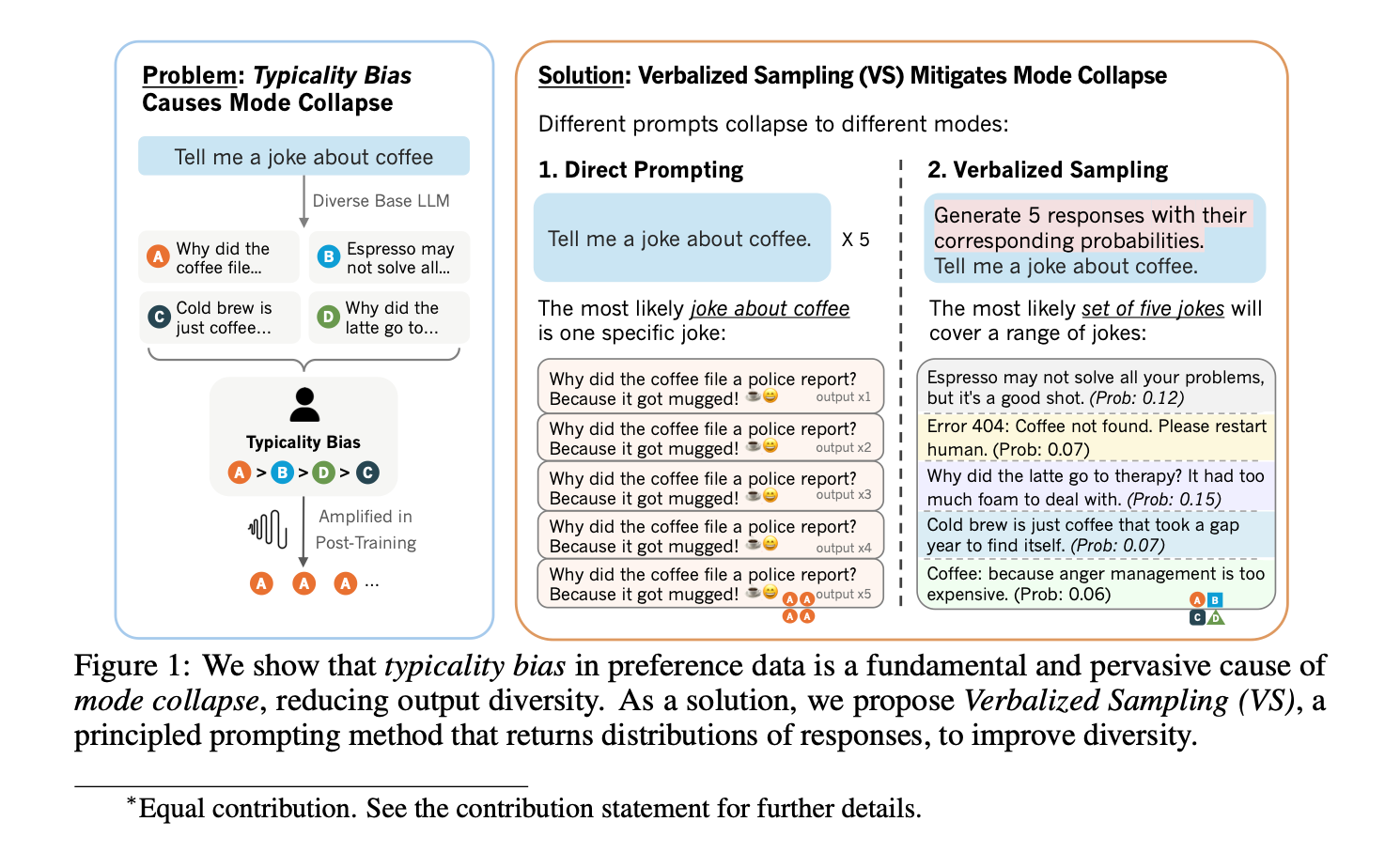
Have you ever encountered the issue where your chat model returns the SAME response no matter how many times you regenerate it? This issue known as mode collapse and researchers from Northeastern University, Stanford University, and West Virginia University have identified a fundamental cause of this problem and developed a simple prompting solution. The root cause for the problem is the annotators’ typicality bias—the human tendency to prefer familiar, conventional text when creating preference datasets—causes aligned LLMs to favor narrow, stereotypical responses over diverse outputs.
The solution they propose is Verbalized Sampling (VS), a training-free prompting method that asks models to generate distributions of responses with corresponding probabilities. Comprehensive experiments across creative writing, dialogue simulation, open-ended QA, and synthetic data generation show VS increases diversity by 1.6-2.1× over direct prompting while maintaining factual accuracy and safety. But there is one downside for this approach which is cost intensive because rather than getting a single response you’re asking N responses with this change.
https://arxiv.org/pdf/2510.01171
News we’re watching
Absurd Workflows: Durable Execution With Just Postgres

Armin Ronacher wrote about his barebones implementation of durable execution.
https://lucumr.pocoo.org/2025/11/3/absurd-workflows/
pg_plan_advice

Robert Haas introduces patches to support user-configurable query plans. While some major databases support query hints, PostgreSQL has famously long avoided this. Certainly a thread to watch closely over the next few years.
Kubernetes v1.34: Moving Volume Group Snapshots to v1beta2

Kubernetes’ latest release includes bug fixes for how Kubernetes does consistent snapshots for a set of volumes. EDB’s Leonardo Cecchi is one of the developers credited in this release of Kubernetes.
https://kubernetes.io/blog/2025/09/16/kubernetes-v1-34-volume-group-snapshot-beta-2/
Moving tables across PostgreSQL instances

Anantha Kumaran talks about migrating a table within Postgres instances using PostgreSQL’s builtin logical replication.
https://ananthakumaran.in/2025/11/02/moving-tables-across-postgres-instances.html
DeepSeek-OCR: Contexts Optical Compression
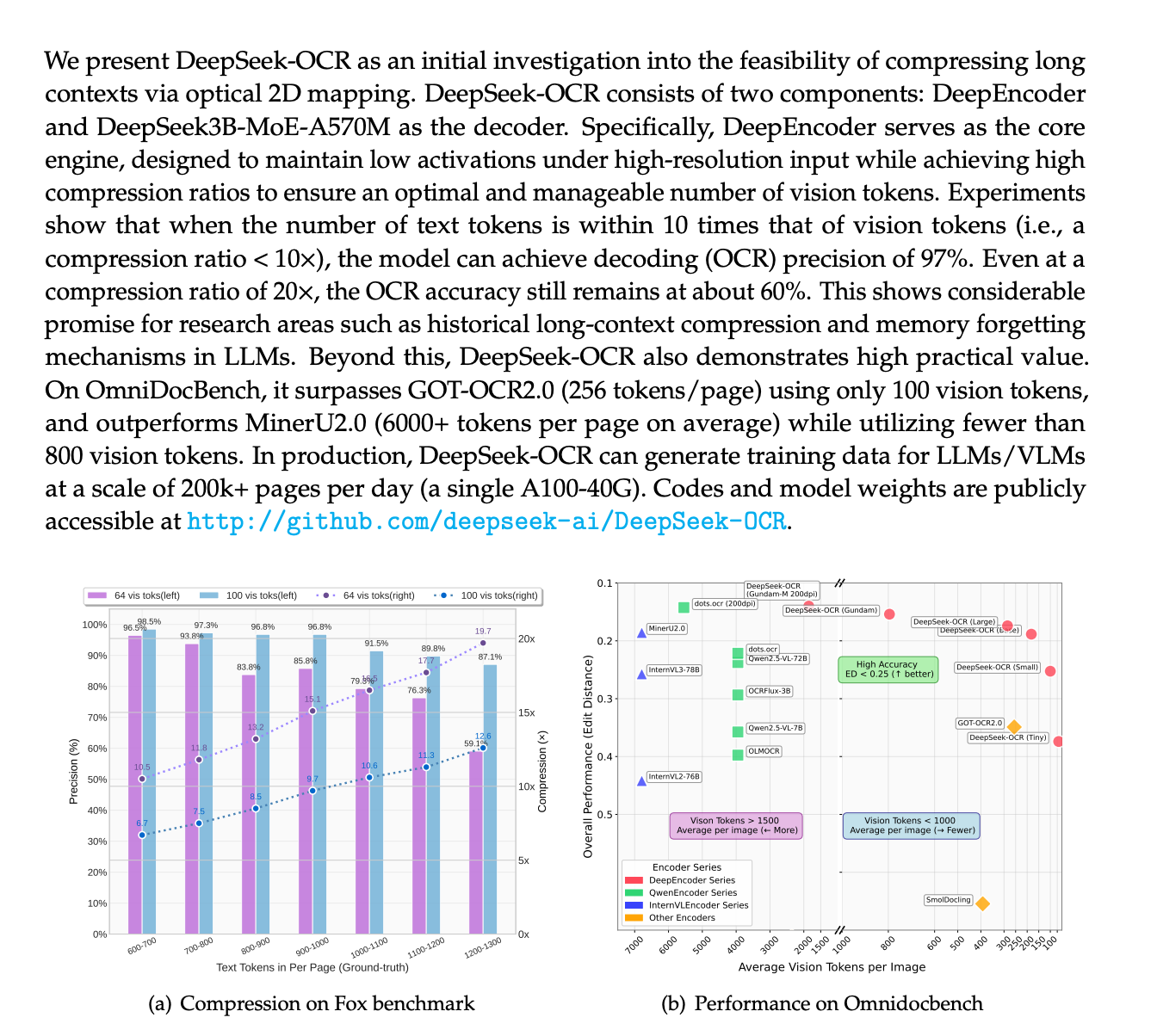
Deepseek has released a new frontier OCR model, and the paper they published about their approach has revealed some interesting points. The most interesting thing they have done is replacing the text tokenizer with visual tokenizer from input. So rather than processing text data they used pixels instead. Text tokenizers are often considered a big bottleneck for LLMs. The team behind DeepSeek-OCR used the visual modality as an efficient compression medium for textual information to solve long-context challenges and memory forgetting mechanisms in LLMs. The research community has started to discuss this as a potential pathway toward AGI.
DeepSeek-OCR demonstrates significant compression efficiency with this change: it can decrease the token size 7–20× compared to models that are using text tokenization on input. In specific tests on the Fox benchmark, documents containing 1200–1300 ground-truth text tokens could still be decoded with 87.1% precision when compressed into only 100 vision tokens (a 12.6× compression). These numbers are quite powerful because in a production setting, a single GPU (A100-40G) can process over 200,000+ pages per day. So you can even run the model in a humble architecture efficiently.
https://www.arxiv.org/pdf/2510.18234
EDB at PGConf EU
PostgreSQL conferences are such a big deal for engineers at EDB. So let’s take a look at what we spoke about last month in Riga!
Barman, past, present, and future of a pioneer community project

Giulio Calacoci and Martín Marqués spoke about the work that’s gone into EDB’s open-source Postgres backup manager over the years.
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7103/slides/780/
Migrating to PostgreSQL: Strategies, Sovereignty and Success
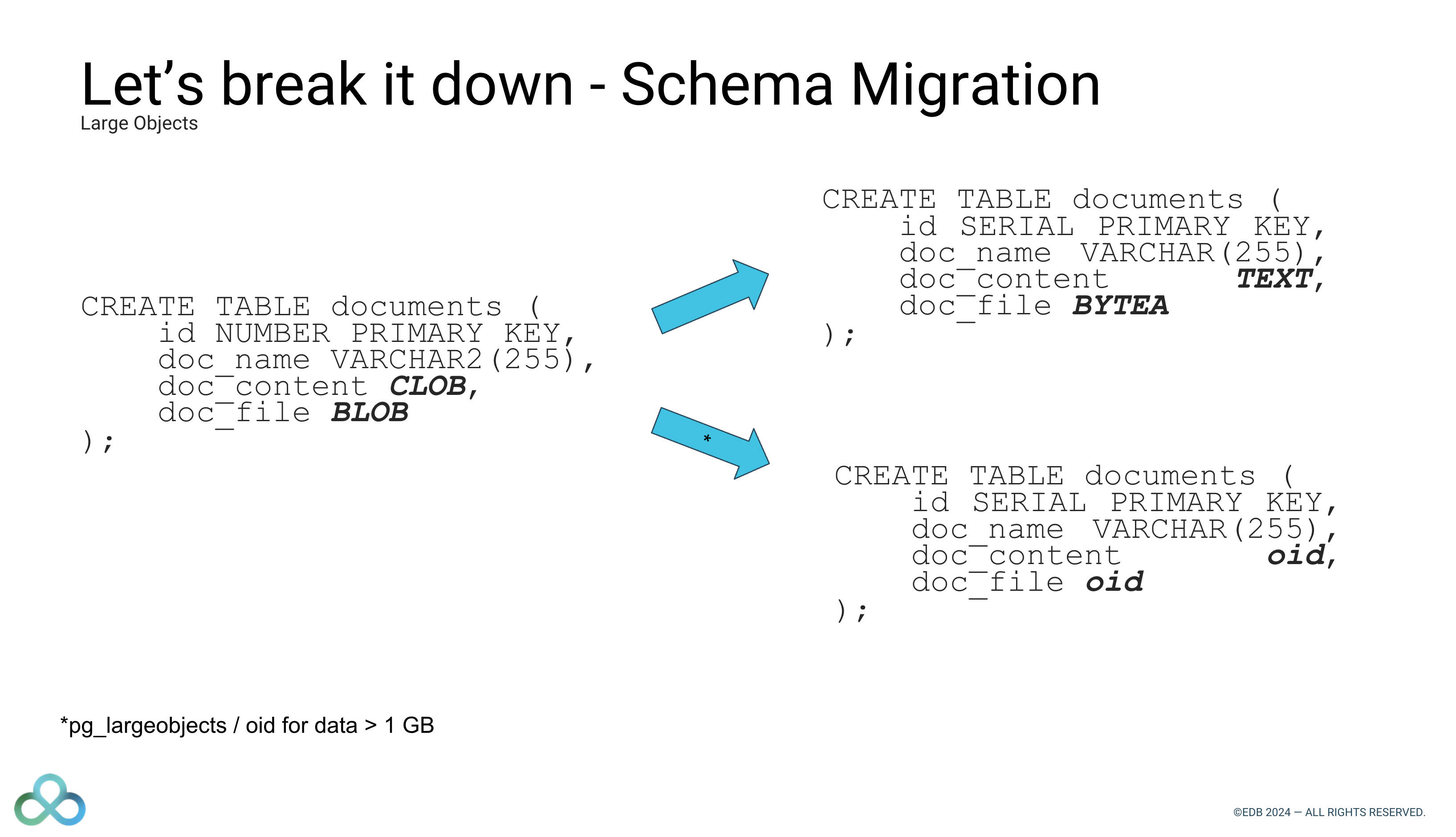
Raphael Salguero spoke about his experience migrating data and workloads from MySQL, Oracle and MS SQL Server to PostgreSQL.
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7084/slides/790/
They grow up so fast: donating your open source project to a foundation (The CloudNativePG story)
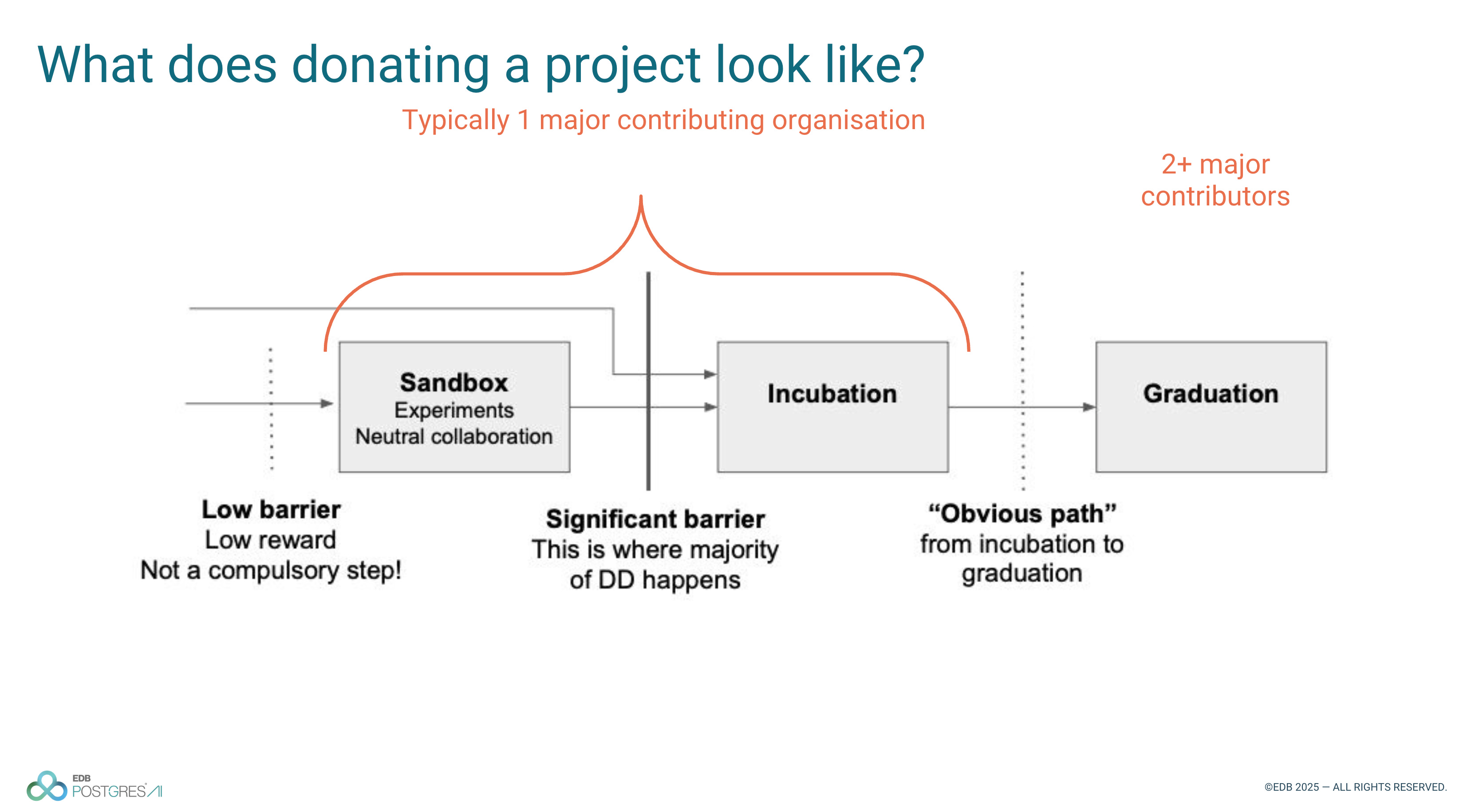
Floor Drees and Gabriele Bartolini spoke about the development of CloudNativePG at EDB and the process of donating ownership of it to the Cloud Native Compute Foundation.
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7021/slides/748/
We have Multiple Concurrent Versions of this Title Trying to Understand MVCC
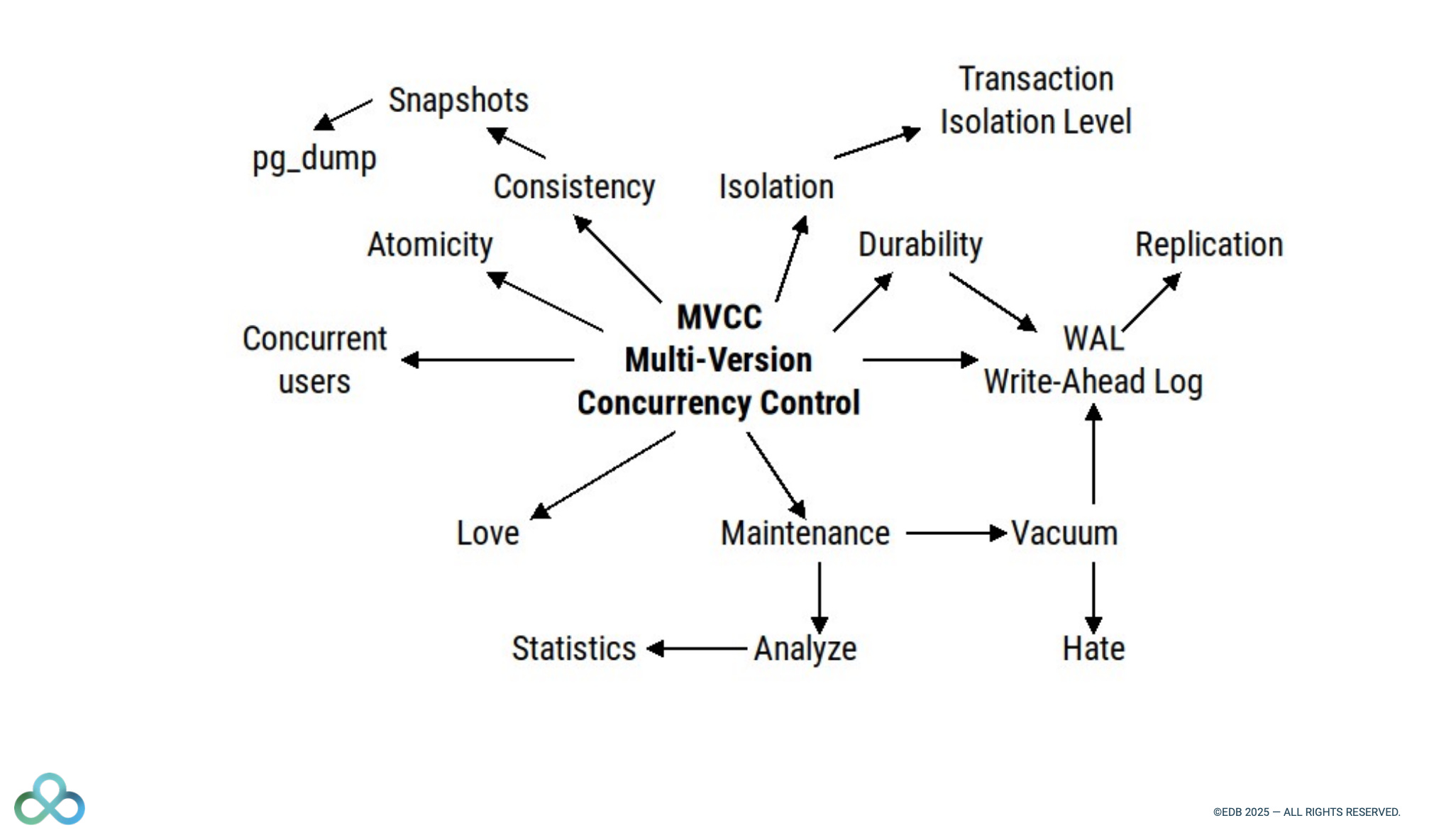
Boriss Mejías (EDB) and Akshat Jaimini (DeepSource) share how MVCC and vacuuming works in Postgres.
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7010/slides/799/
Data modeling with PostgreSQL at the core of Software Development
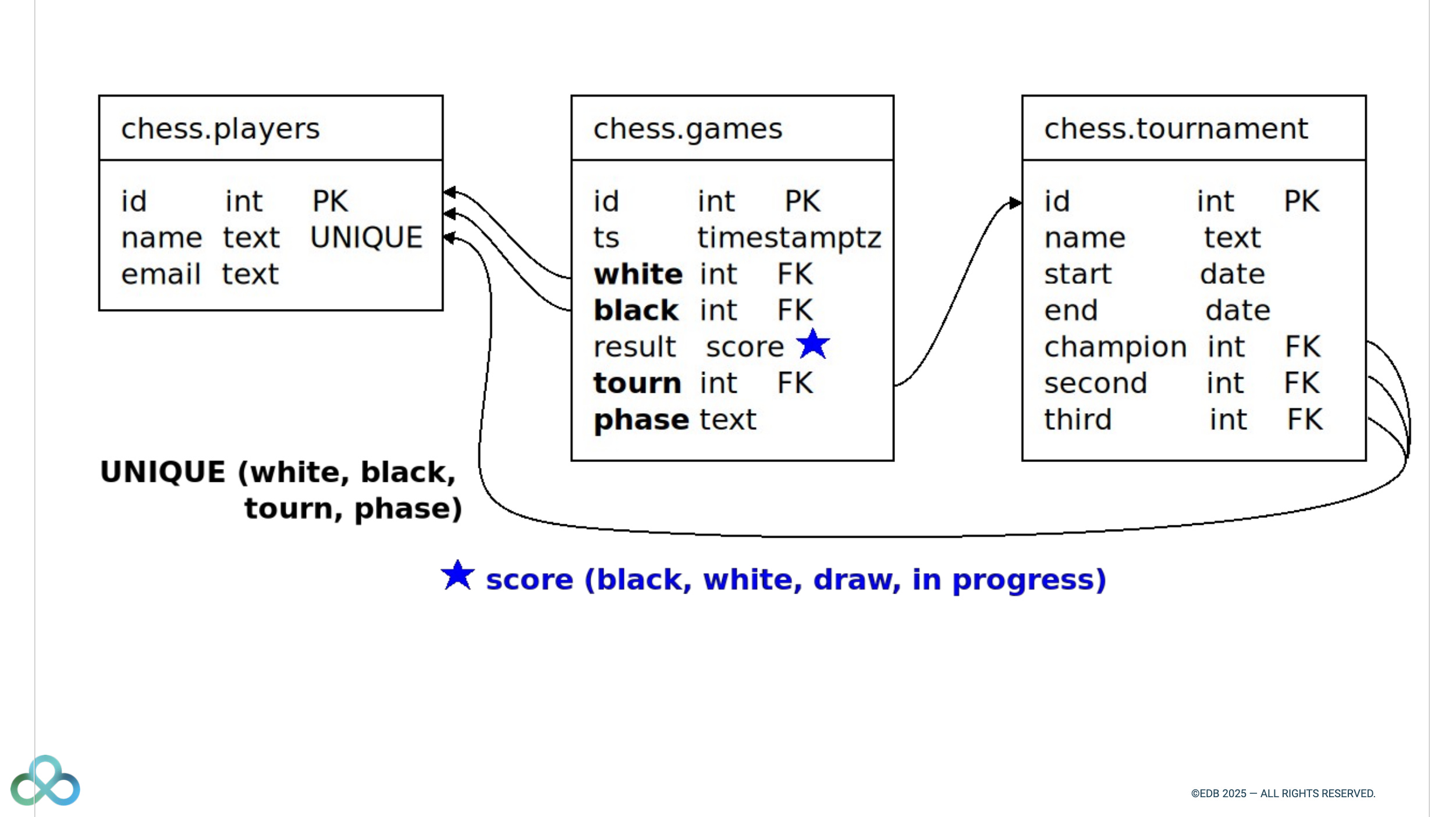
Boriss Mejías models a chess tournament in PostgreSQL!
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7009/slides/798/
Table Repacking, done right

Álvaro Herrera (EDB) and Antonín Houska (Cybertec) spoke about how VACUUM came to have its current behavior from very different origins at Berkeley, the history of extensions for dealing with MVCC bloat in PostgreSQL, and the work they are doing on a new REPACK command planned for PostgreSQL 19.
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7094/slides/772/
Storage Performance Matters: Benchmarking PostgreSQL on Kubernetes
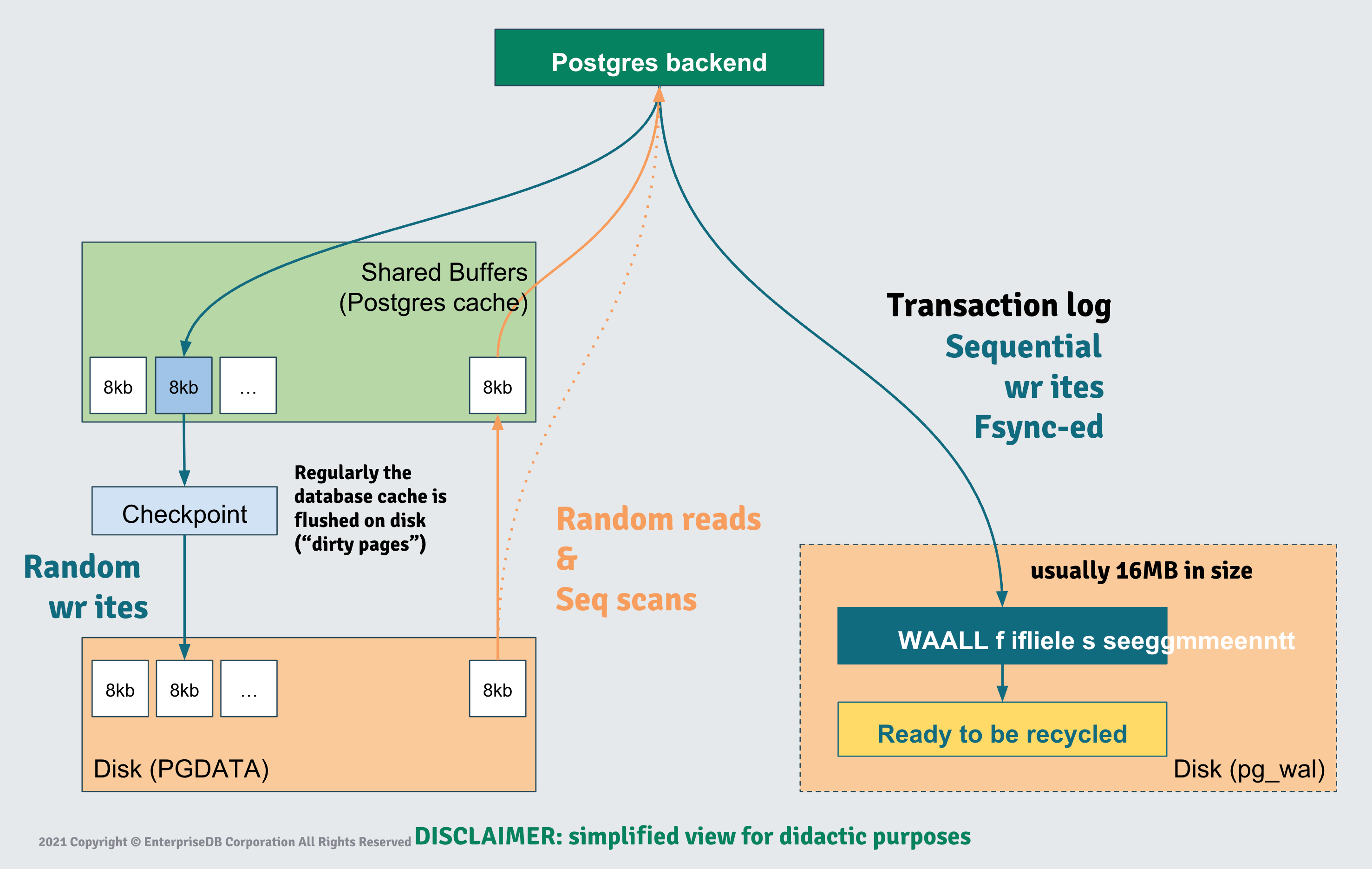
Jonathan Battiato spoke about how to debug faulty hardware or bottlenecks slowing down PostgreSQL (or CloudNativePG), which is really no different whether or not you’re in containers.
https://www.canva.com/design/DAG2brkvrrw/CqVhbeaXeDiisvBWNWlr6Q/view
Unified Observability: Monitoring Postgres Anywhere with OpenTelemetry

Yogesh Jain spoke about how to monitor PostgreSQL, even within a Kubernetes environment like CloudNativePG, and even how you can integrate your monitoring with an LLM to answer high level questions like “Is my database latency higher than usual right now?”
https://www.postgresql.eu/events/pgconfeu2025/sessions/session/7035/slides/762/
From Transactions to Intelligence: Postgres for Open AI & Analytics
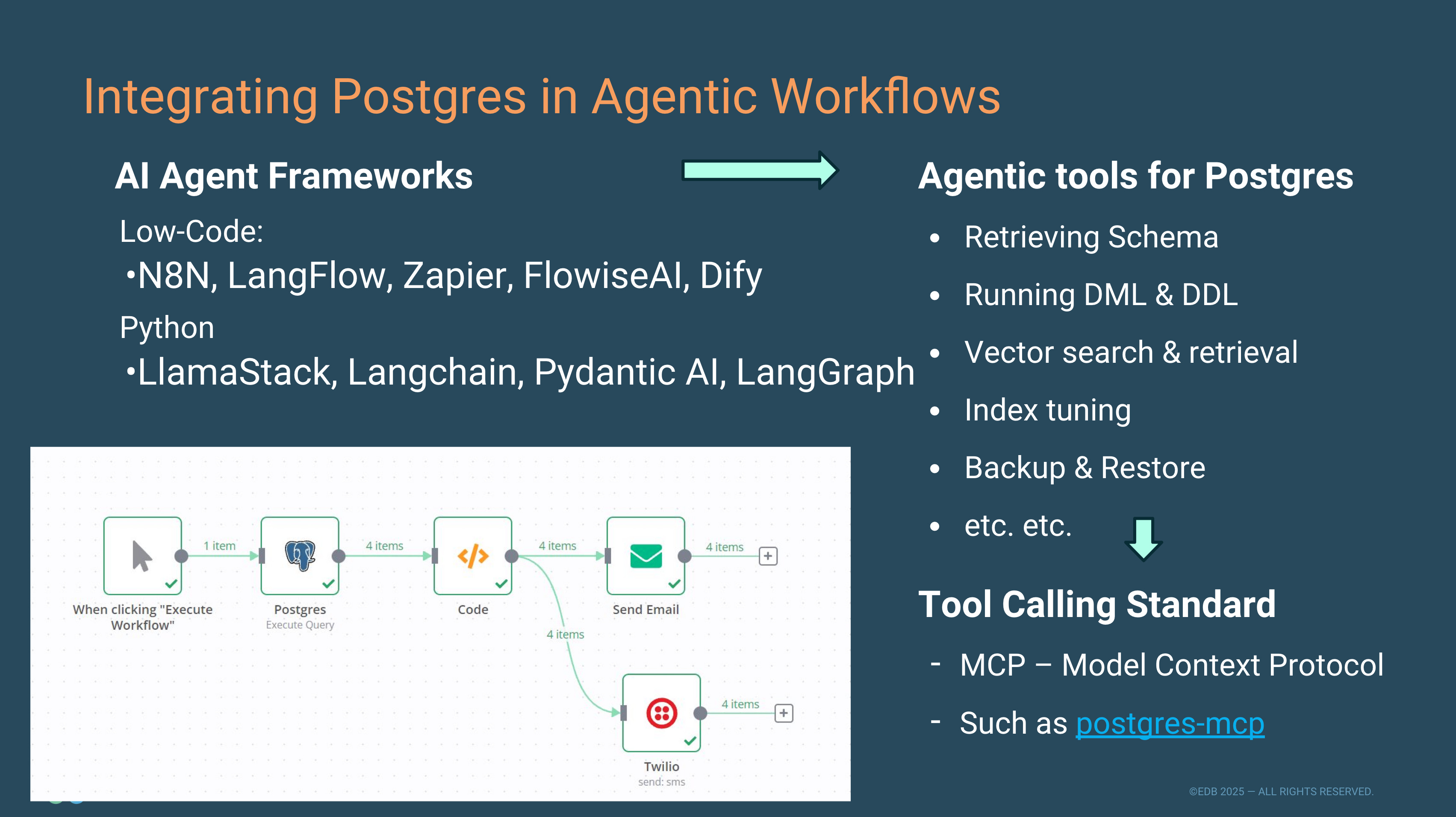
Torsten Steinbach explores three paths through which PostgreSQL is evolving to support modern workloads like analytics and AI:
First, the organic path, where Postgres itself grows new capabilities — think WarehousePG for analytics or pgvector and friends for AI. Second, the hybrid path, where Postgres joins forces with other open-source engines like DataFusion and open metadata frameworks such as Iceberg REST catalogs. And third, the augmented path, where Postgres extends into entirely new ecosystems — becoming a first-class citizen in agentic AI through robust MCP-driven tooling.
https://www.canva.com/design/DAG2hBUQHTo/N-ZScITaEgjYXghf_CtI9w/view
From the EDB Team
The journey to virtual generated columns
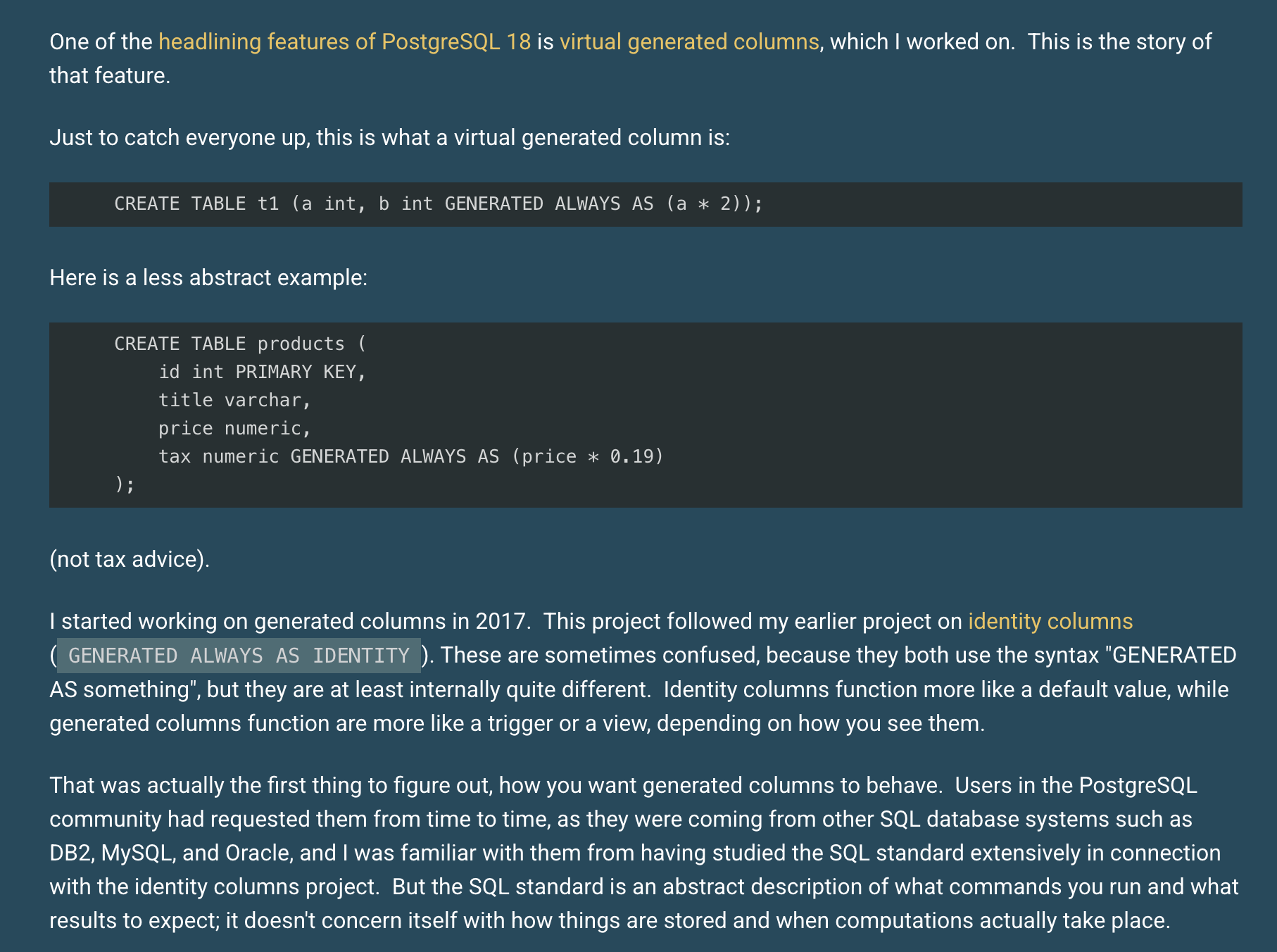
Peter Eisentraut shares the history, current state, and future of the development of virtual generated columns in PostgreSQL.
https://www.enterprisedb.com/blog/journey-virtual-generated-columns
Debugging processes across container boundaries on Kubernetes
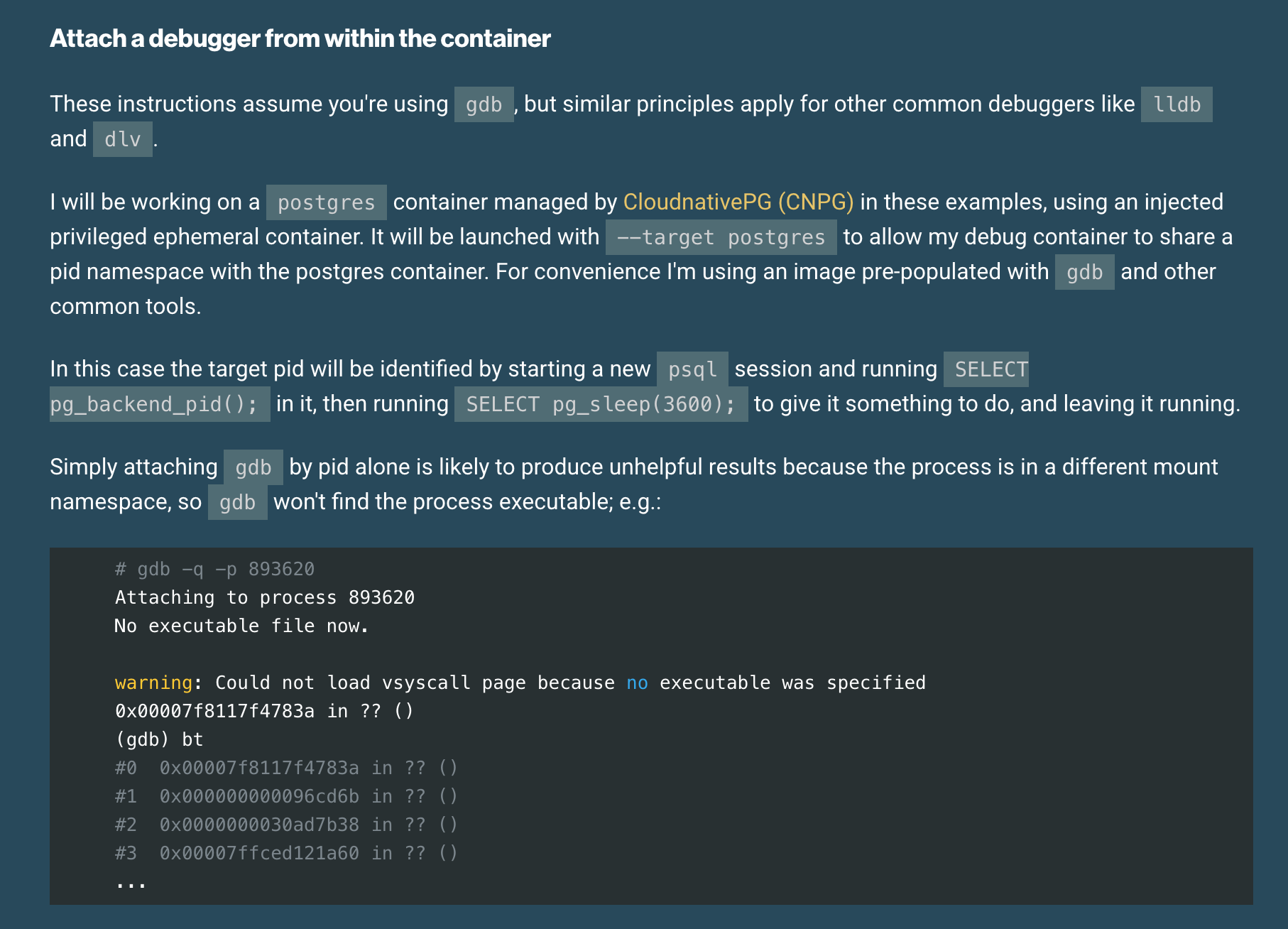
Craig Ringer shows how to inject a debug container B into the namespace of a running container A, which makes it possible to debug a locked-down application container without swapping application container images or even restarting the application container.
https://www.enterprisedb.com/blog/debugging-processes-across-container-boundaries-kubernetes
AI Agent Development and Optimization Series (Part 3): Smart Architecture Design & Optimization
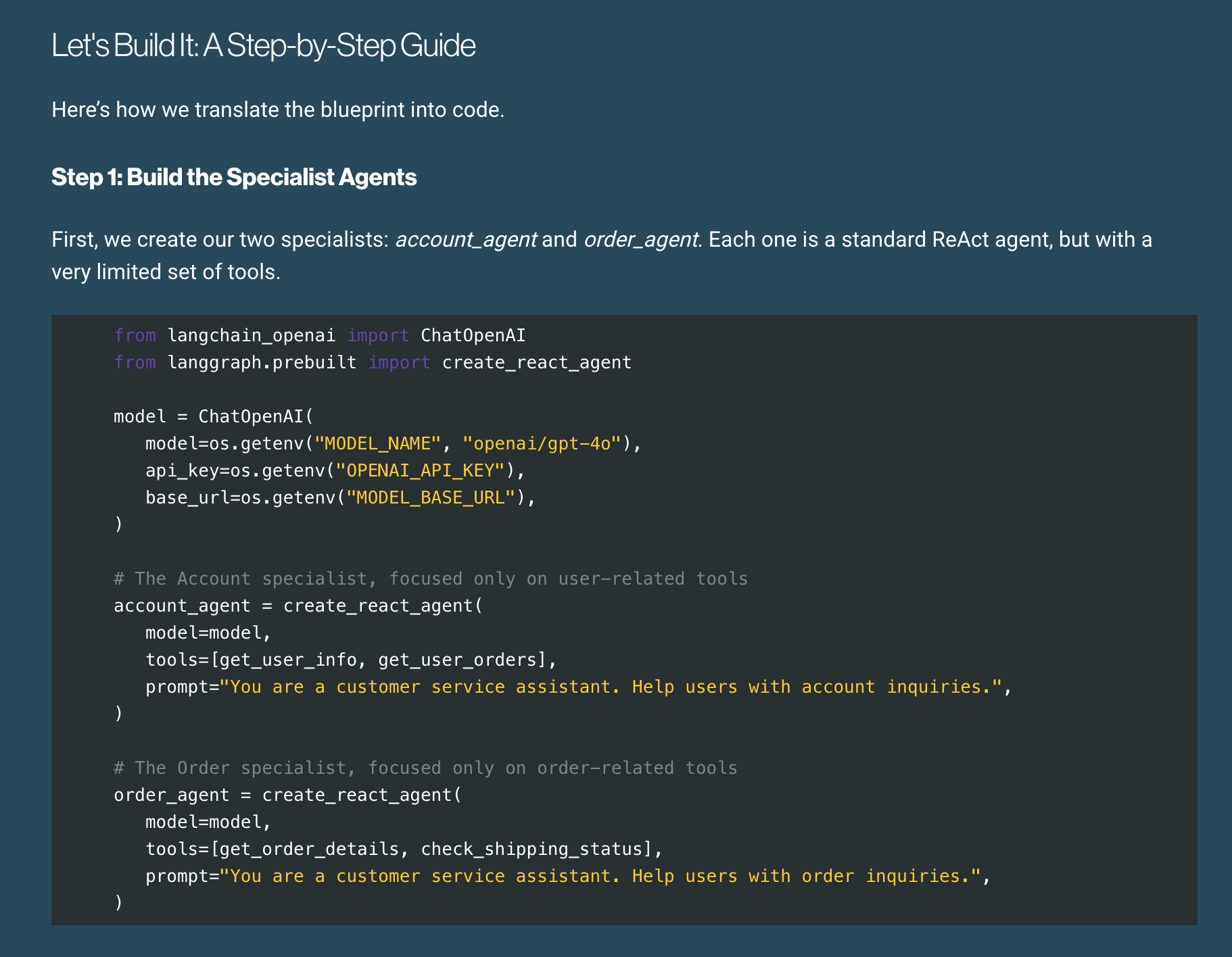
Finnick Huo continues his series on developing AI agents; thinking about improved performance, lower cost, better reliability, and maintainability.
Transaction pooling for Postgres with pgcat
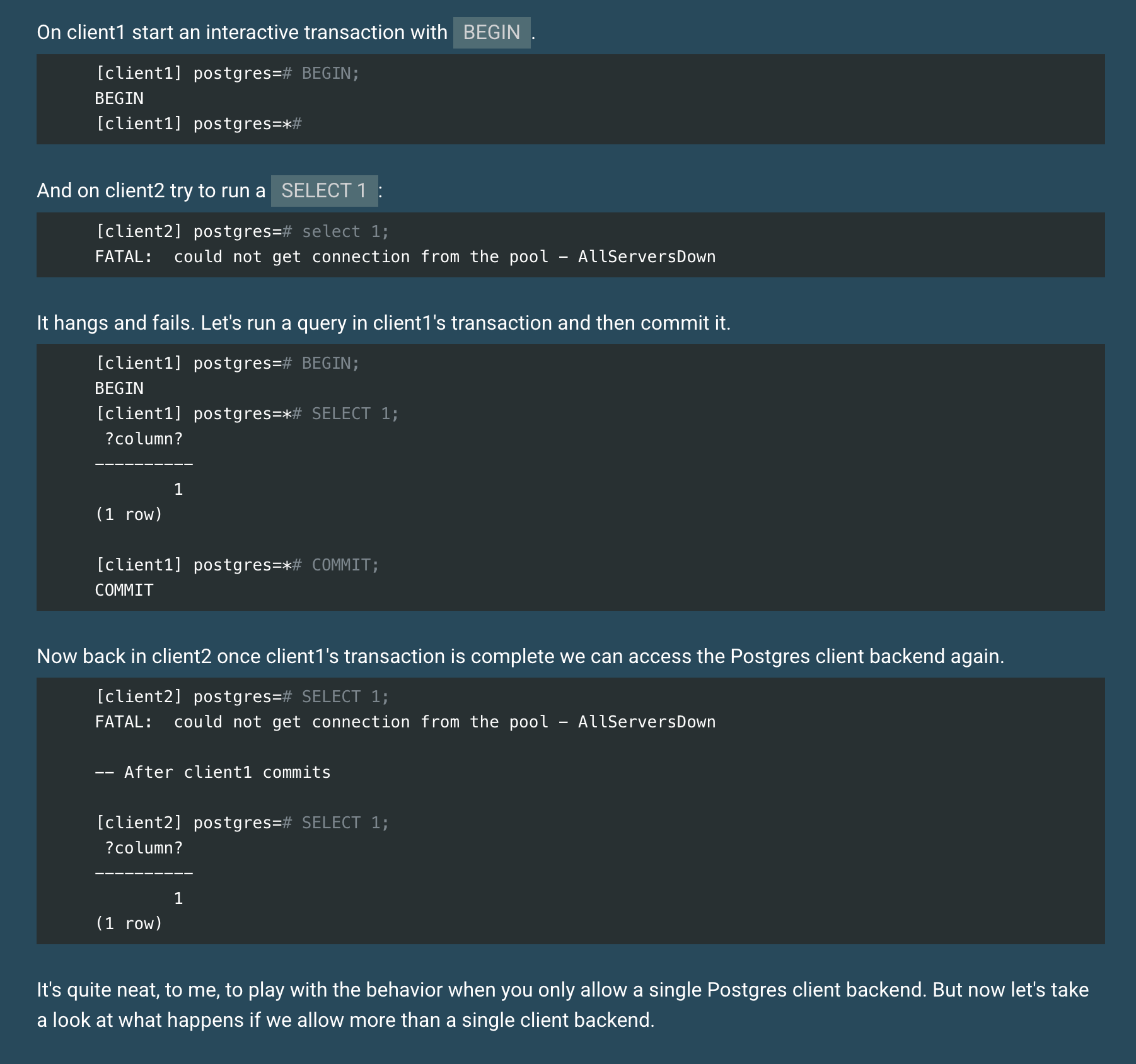
Phil Eaton explores the behavior of connection poolers with pgcat running in transaction pool mode.
https://www.enterprisedb.com/blog/transaction-pooling-postgres-pgcat
How to implement a one-to-one relation in pgAdmin 4 using the ERD tool
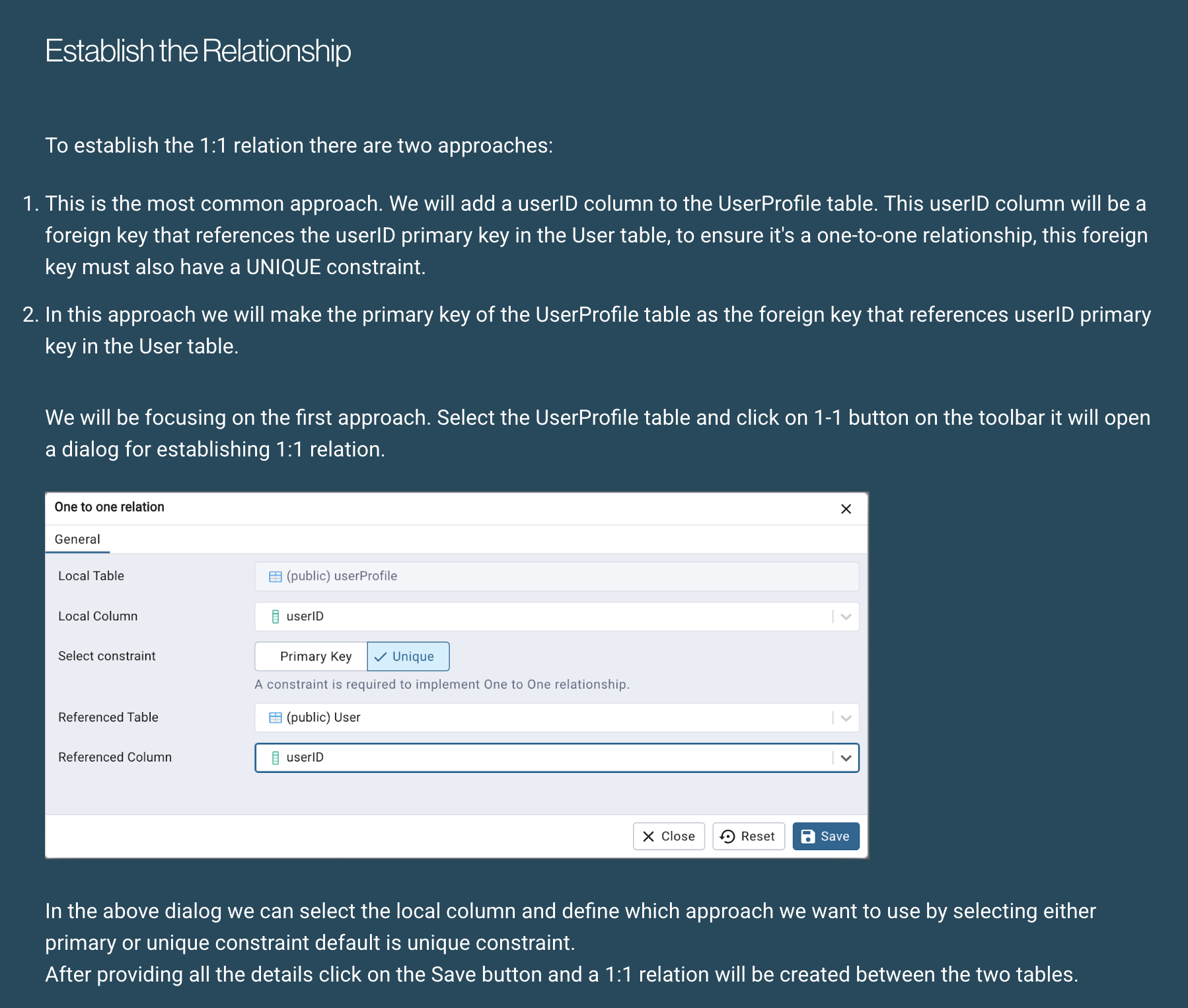
Pravesh Sharma shows how to create Entity-Relationship Diagrams, which help you visualize the structure of your data, in pgAdmin 4.
https://www.enterprisedb.com/blog/how-implement-one-one-relation-pgadmin-4-using-erd-tool
Building MCP Servers from Protobuf (Part4) - Insights from Running MCP Tools in Practice

Charlie Zhang continues his series on building MCP servers talking about key challenges with auto-generated MCP tools.
How to scrape an undeclared Port on a Pod with prometheus-operator
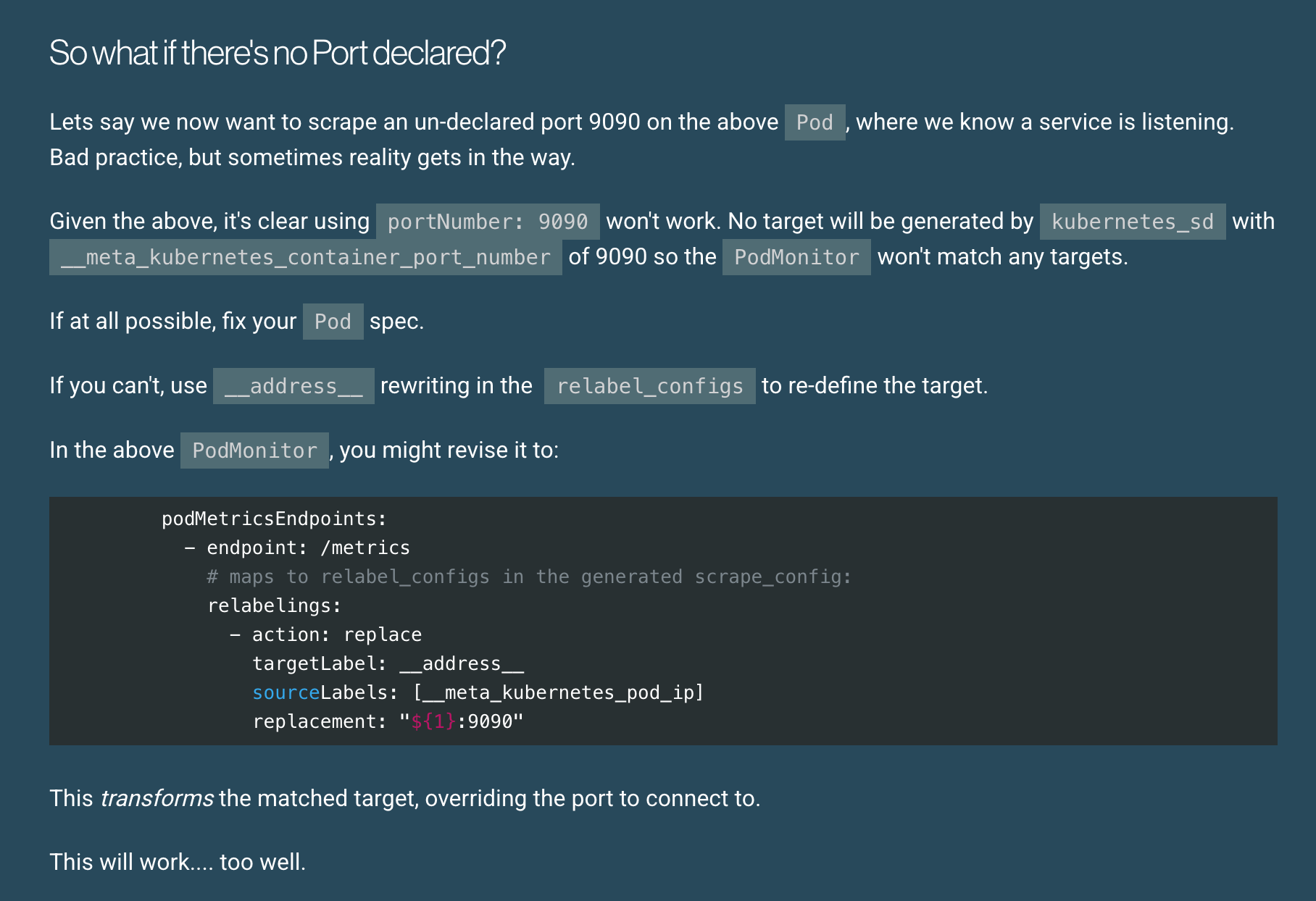
Craig Ringer shares why, and how, Prometheus selects Kubernetes targets to scrape.
https://www.enterprisedb.com/blog/how-scrape-undeclared-port-pod-prometheus-operator
Part 2: PostgreSQL’s incredible trip to the top with developers

Tom Kincaid continues his series examining PostgreSQL’s rise to the top of some developer surveys, considering the initial popularity of MySQL and what happened between the two databases to lead to today’s standings.
https://www.enterprisedb.com/blog/part-2-postgresqls-incredible-trip-top-developers
Seamless Updates: Auto Update of pgAdmin 4 Desktop App on macOS

Anil Sahoo talks about how pgAdmin 4’s new auto-update feature works under the hood, including guiding you through how to find the feature’s implementation in code.
https://www.enterprisedb.com/blog/seamless-updates-auto-update-pgadmin-4-desktop-app-macos
Measuring Query Latency the Hard Way: An Adventure in Impractical Postgres Monitoring
P99 CONF is a virtual event for developers who care about P99 percentiles and high-performance, low-latency applications. Our Senior Product Manager Simon Notley delivered a session at the virtual event: “Measuring Query Latency the Hard Way: An Adventure in Impractical Postgres Monitoring”. pg_stat_activity should explicitly not be used for measuring query latency, but pursuing terrible ideas is Simon’s idea of fun. And it will be yours too, we highly recommend watching.
CloudNativePG 1.28.0 RC1 Released!

Gabriele Bartolini announces the release candidate of CloudNativePG 1.28 with support for quorum-based failover and declarative foreign data management.
https://cloudnative-pg.io/releases/cloudnative-pg-1-28.0-rc1-released/
From Side Projects: Why We Chose Rust for Postgres + AI
Noah Baculi spoke at the Seattle Postgres meetup earlier this year on building AI extensions for PostgreSQL in Rust with pgrx. The recording of his talk is now up!
Until next time
We hope you enjoyed this edition of the EDB Engineering Newsletter! Consider joining the PostgreSQL Hacker Mentoring Discord or the CloudNativePG Slack to get involved!
The EDB Engineering Team

A chunk of the EDB team who went to Riga for PGConf.EU. (The rest of the team there was in sessions / chatting. 😉)