
EDB Engineering Newsletter #11
PostgreSQL 18 is released!
Welcome to the 11th edition of the EDB Engineering Newsletter! Where we share happenings in the data world that the team has enjoyed discussing, as well as other news about what the EDB Engineering team is up to.
Each release of PostgreSQL is a really big deal for us, so you’ll forgive us if there is quite a lot to talk about on the topic in this edition! Beyond the significant contributions EDB developers made directly to the release, we also wrote about some of the new features in this release and we dug into some of the stories of the development behind the scenes.
PostgreSQL 18
From the official release page:
PostgreSQL 18 improves performance for workloads of all sizes through a new I/O subsystem that has demonstrated up to 3× performance improvements when reading from storage, and also increases the number of queries that can use indexes. This release makes major-version upgrades less disruptive, accelerating upgrade times and reducing the time required to reach expected performance after an upgrade completes.
Developers also benefit from PostgreSQL 18 features, including virtual generated columns that compute values at query time, and the database-friendly uuidv7() function that provides better indexing and read performance for UUIDs. PostgreSQL 18 makes it easier to integrate with single-sign on (SSO) systems with support for OAuth 2.0 authentication.
At least 23 EDB engineers were acknowledged “as patch authors, committers, reviewers, testers, or reporters of issues“:
Álvaro Herrera
Amul Sul
Andrew Dunstan
Bruce Momjian
Euler Taveira
Gabriele Bartolini
Ian Barwick
Jacob Champion
Jakub Wartak
Jian He
Mahendra Singh Thalor
Marco Nenciarini
Mark Dilger
Matheus Alcantara
Niccolò Fei
Peter Eisentraut
Phil Eaton
Richard Guo
Robert Haas
Rushabh Lathia
Srinath Reddy
Suraj Kharage
https://www.postgresql.org/about/news/postgresql-18-released-3142/
Let’s take a look at what EDB engineers wrote about this release.
Run PostgreSQL 18 on Kubernetes Today with CloudNativePG
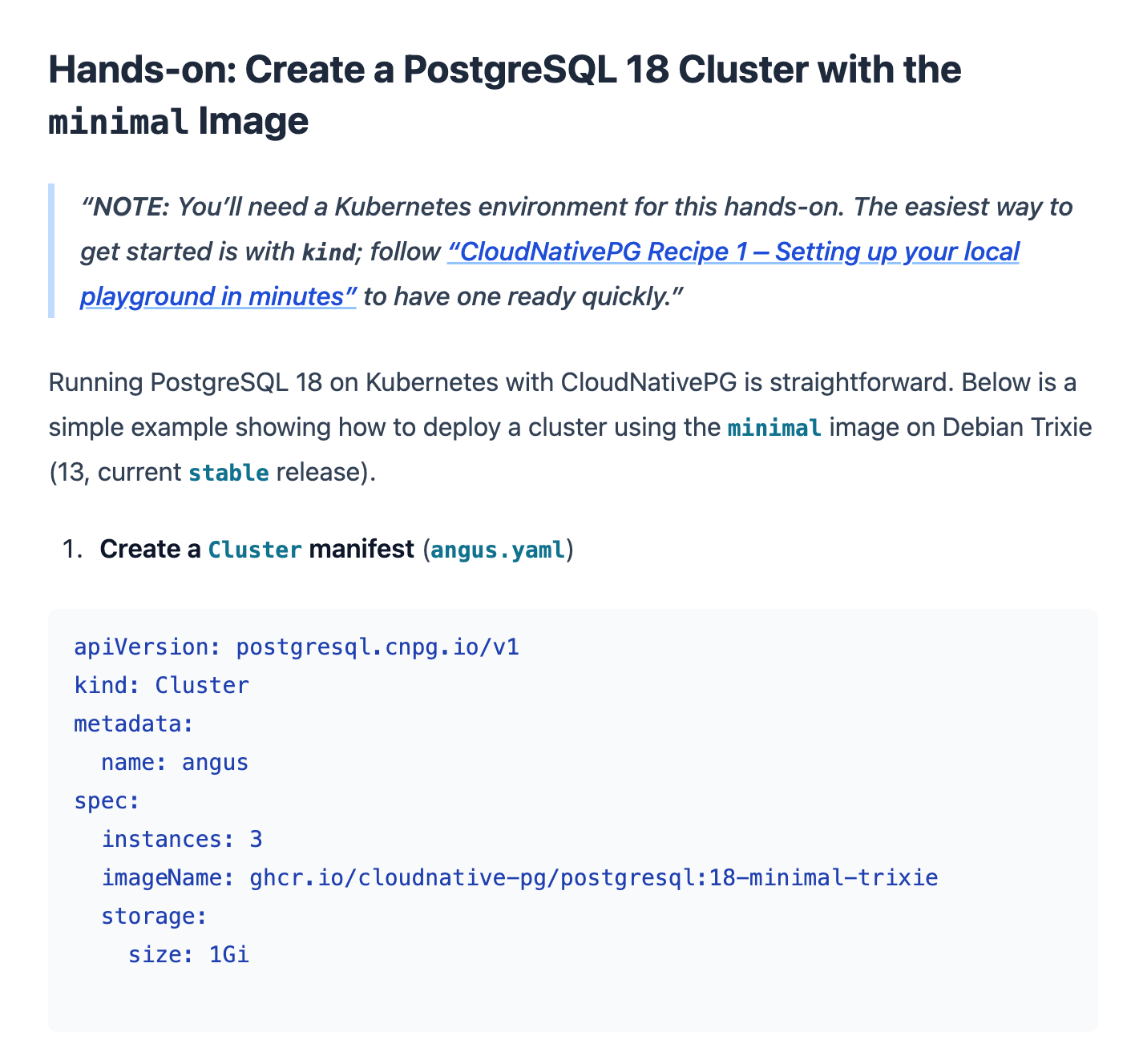
Gabriele Bartolini describes how to try out PostgreSQL 18 with CloudNativePG.
Changes to NOT NULL in Postgres 18
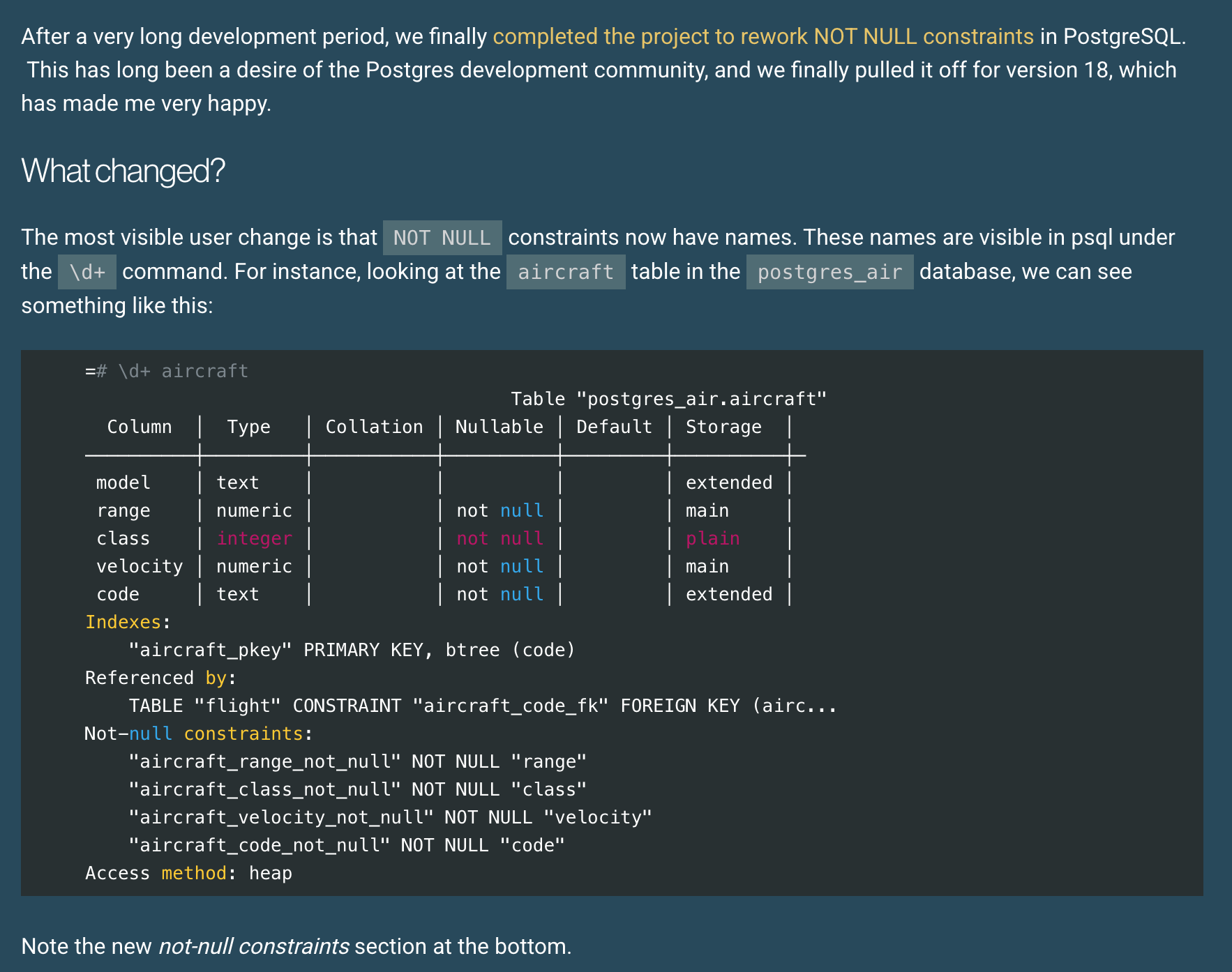
Álvaro Herrera writes about changes to NOT NULL constraints in PostgreSQL 18; including work done by EDB engineers, Jian He, Amul Sul, Suraj Karage, and Rushabh Lathia.
https://www.enterprisedb.com/blog/changes-not-null-postgres-18
Fine Tuning Incremental Backup

Robert Haas writes about how PostgreSQL’s incremental backup feature evolved alongside the needs of its users, including EDB’s backup manager, barman.
https://www.enterprisedb.com/blog/fine-tuning-incremental-backup
What’s new in PostgreSQL 18 RPMs, and EDB’s contribution to PostgreSQL RPM packaging

Devrim Gündüz writes about how RPM packages of PostgreSQL work and what’s new in PostgreSQL 18.
On Developing OAuth

Jacob Champion writes about his years-long work to add OAuth support to PostgreSQL, new in 18.
https://www.enterprisedb.com/blog/developing-oauth
PostgreSQL 18’s OAuth2 Authentication
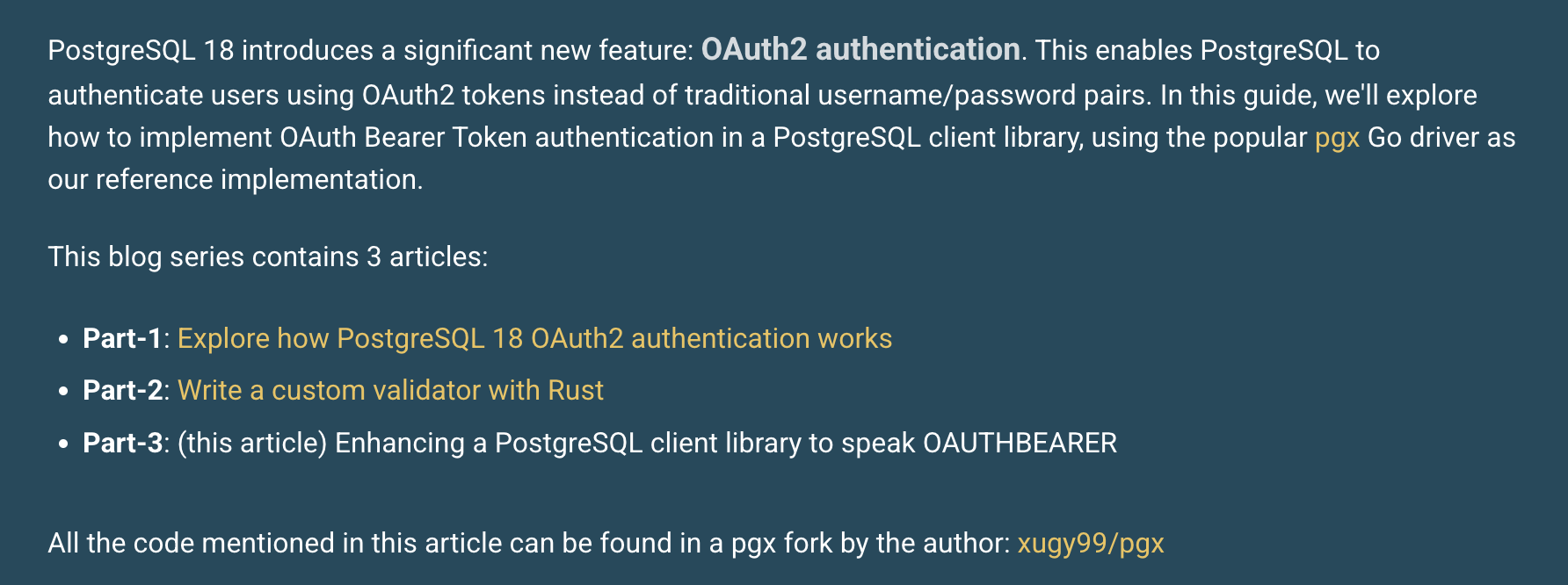
Guang Yi Xu wrote a three-part series on how one might adjust an existing PostgreSQL client in Go to support PostgreSQL 18’s new OAuth feature.
The journey to virtual generated columns

Peter Eisentraut talks through the history and development of generated columns in PostgreSQL: from PostgreSQL 12’s support for stored (i.e. update-on-write) generated columns to PostgreSQL 18’s virtual (i.e. compute-on-read) generated columns.
https://www.enterprisedb.com/blog/journey-virtual-generated-columns
A team effort
It takes a village to develop and support PostgreSQL. We applaud and congratulate the work done by the entire PostgreSQL community to make this release happen. Thank you!
Now back to our regular programming.
Analysis we're following
Hints for Computer System Design

We enjoyed re-reading Butler Lampson’s 1983 paper with some hard-earned and opinionated ideas on the development and design of software.
https://dl.acm.org/doi/pdf/10.1145/773379.806614
Losing Data is Harder Than I Expected, and Testing CloudNativePG Preferred Data Durability
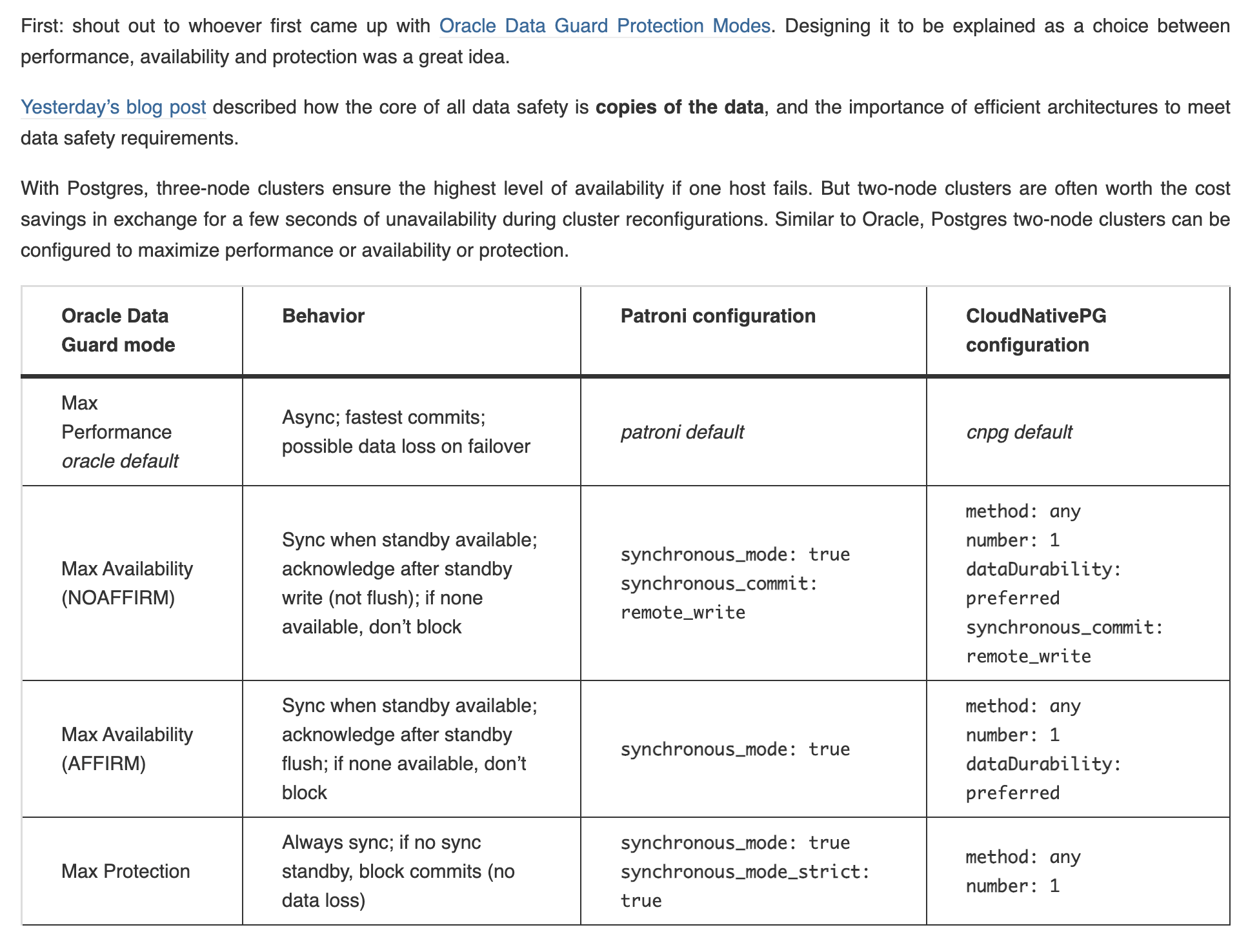
Jeremy Schneider has continued a great series exploring CloudNativePG with Jepsen in two new posts; looking at what he calls Max Performance, Max Availability, and Max Protection modes.
Across thousands of minutes of testing, I did not observe a single instance of data loss with sync enabled under these test configurations.
https://ardentperf.com/2025/09/28/losing-data-is-harder-than-i-expected/
https://ardentperf.com/2025/10/05/testing-cloudnativepg-preferred-data-durability/
Gödel Test: Can Large Language Models Solve Easy Conjectures?

This paper introduces a benchmark to see if frontier LLMs can write correct proofs for very simple, new conjectures. GPT-5 gave near-complete solutions on 3 of 5 combinatorial-optimization tasks and even produced one original, conjecture-refuting guarantee, but it failed when the proof required stitching ideas across papers.
Now the community is split: Daniel Litt who is an Assistant Professor at Toronto University argues that calling a proof “nearly correct” is misleading—almost correct can still be wrong. Hype or not, the direction is clear: these models move fast, but verification and reliability are still the main bottlenecks.
https://arxiv.org/pdf/2509.18383
Why do LLMs freak out over the seahorse emoji?

Theia Vogel looks at how LLMs work under the hood to explain why many different models produce the wrong result when asked: “Is there seahorse emoji?”
https://vgel.me/posts/seahorse/
News we’re watching
F3: The Open-Source Data File Format for the Future

A group of researchers that include Wes McKinney and Andy Pavlo have published a new “future-proof” file format for analytics data that, among other things, embeds WebAssembly instructions for decoding data within the file.
https://db.cs.cmu.edu/papers/2025/zeng-sigmod2025.pdf
An AI Index for all our customers
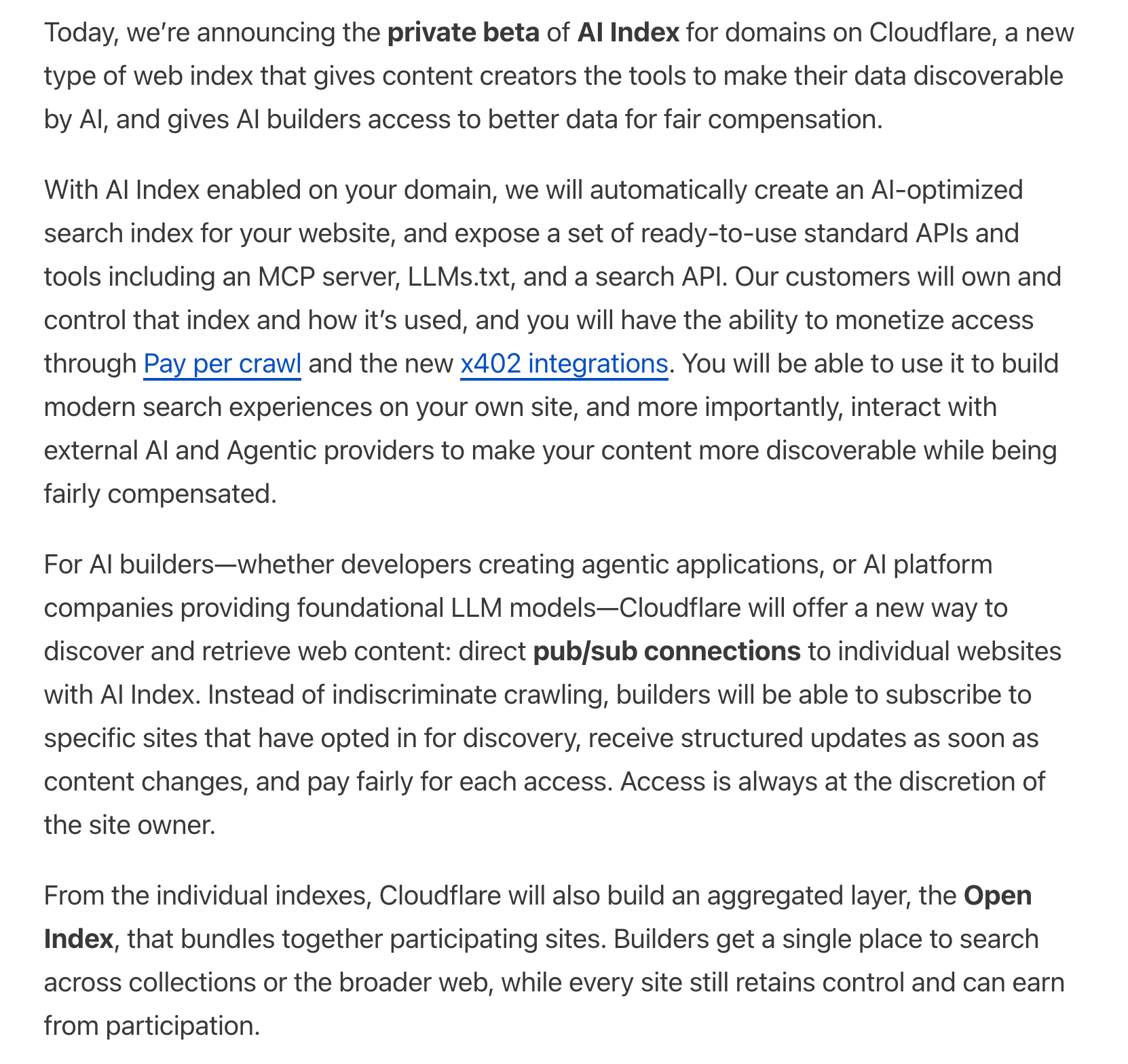
Cloudflare is introducing an AI Index for any domain on their platform. When enabled, Cloudflare auto-builds and maintains an AI-optimized index of your site that you own and control, updating in real time as your content changes. For AI builders, the workflow shifts from blind crawling to subscribing to sites for those opt in by receiving structured updates in real time and paying fairly per access, always at the site owner’s discretion.
This approach seems designed to address several pain points in the current system. Content creators currently have little control or compensation when their content is crawled for AI training. AI companies waste significant resources on repeated crawling and dealing with unstructured data. This is quite an interesting development in how content discovery and AI training data might work in the future especially when currently leaders in AI field complaining of lack of an access to the organic and private data.
https://blog.cloudflare.com/an-ai-index-for-all-our-customers/
AI usage trends from Google and OpenAI

Google and OpenAI have released reports on AI usage trend this month, back to back.
Google’s 2025 DORA Report surveyed nearly 5,000 technology professionals and found AI adoption among software developers reached 90%, it was 76% last year. Developers now spend a median of two hours daily working with AI, with 65% heavily relying on it. Over 80% report productivity gains and 59% see improved code quality. Top use cases are writing new code (71%), modifying code (66%), and documentation (64%). The report reveals a “trust paradox”: only 24% highly trust AI while 30% trust it little or not at all, yet most still use it as a supportive tool rather than a substitute for human judgment.
https://blog.google/technology/developers/dora-report-2025/
OpenAI has focused on a wider range of usage for ChatGPT. The research analyzed 1.5 million conversations from consumer accounts, though it’s worth noting this hasn’t been peer-reviewed yet.
One of the most striking findings is the shift toward personal rather than professional use. Non-work-related messages jumped from 53% a year ago to 73% by June 2025, suggesting ChatGPT is becoming woven into the fabric of daily life beyond just workplace productivity. There’s a notable divide between personal and professional use patterns. At work, writing was the dominant use case at 40% of work-related messages in June. The researchers framed this through an “Asking, Doing, and Expressing” perspective. Overall, about half of all messages were “Asking” behavior, suggesting people value ChatGPT primarily as an advisor. But for work-related messages specifically, 56% were “Doing” activities, meaning people were using it to actually perform job tasks like writing.
From the EDB Team
The Evolution of Logical Replication in PostgreSQL: A Firsthand Account

Petr Jelinek shares the history of logical replication and high availability for PostgreSQL as he experienced and contributed to it over the decades.
https://www.enterprisedb.com/blog/evolution-logical-replication-postgresql-firsthand-account
AI search with style: Fashion on OpenShift AI with EDB
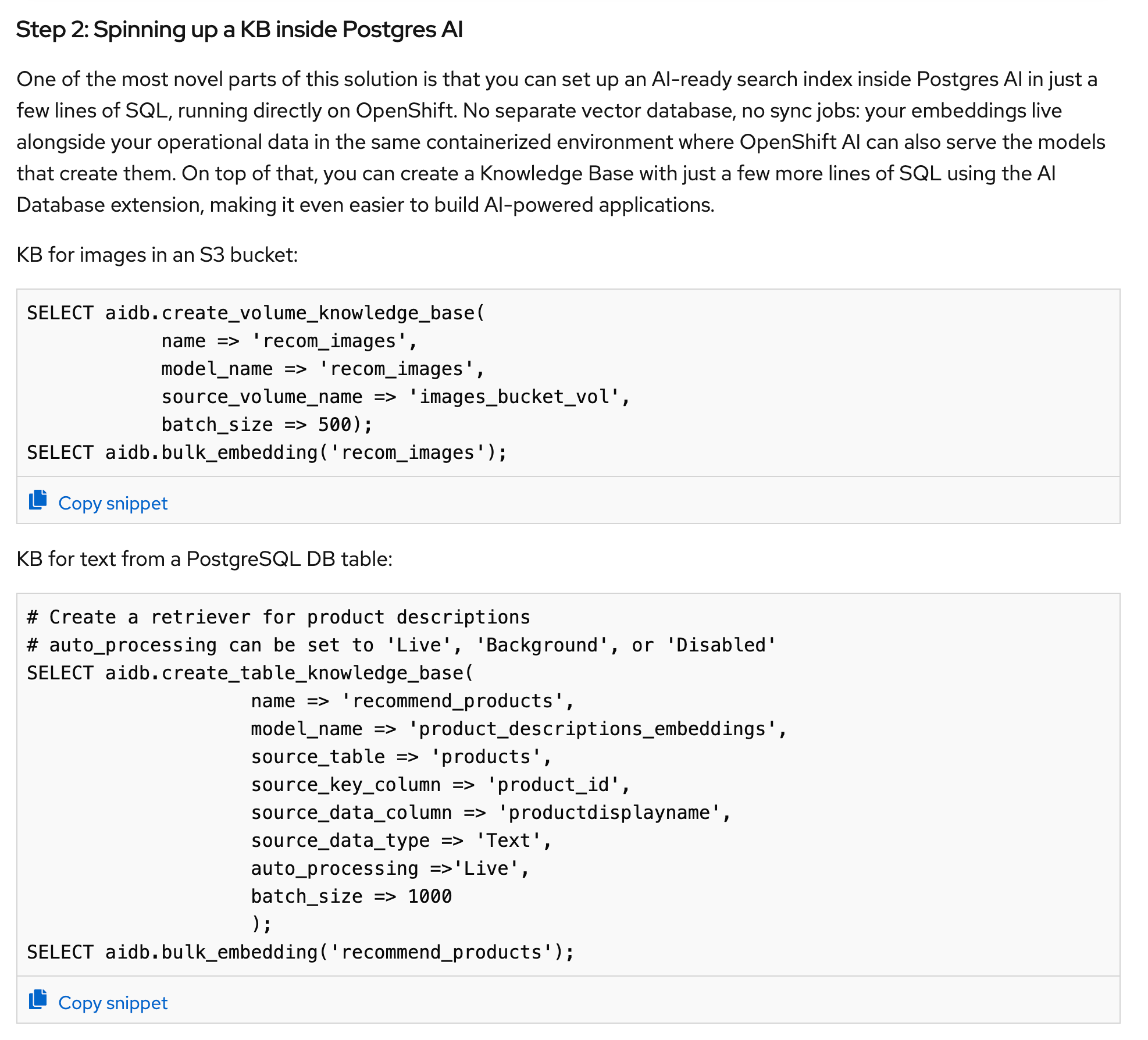
Bilge Ince teamed up with Shane Heroux of Red Hat to publish this tutorial on building an AI-powered search engine for a hypothetical fashion e-commerce business, using EDB Postgres AI and OpenShift.
https://developers.redhat.com/articles/2025/09/10/ai-search-style-fashion-openshift-ai-edb
Barcelona beginnings: onboarding new PostgreSQL contributors

Floor Drees writes about a new internal program at EDB, Developer U, run by long-time PostgreSQL contributor, Andrew Dunstan, that aims to get developers from all different backgrounds at EDB contributing to PostgreSQL.
https://www.enterprisedb.com/blog/barcelona-beginnings-onboarding-new-postgresql-contributors
A simple clustering and replication solution for Postgres
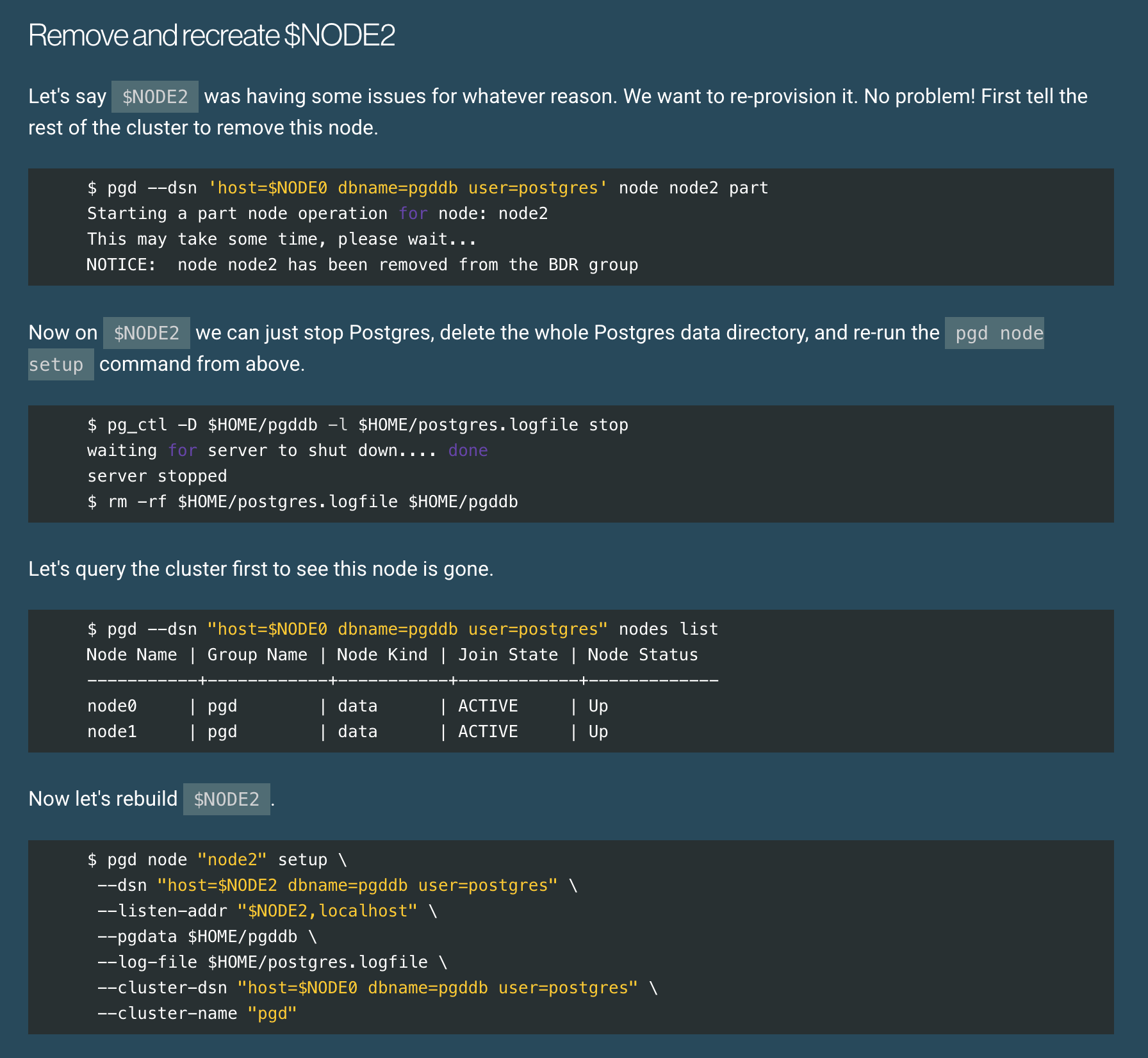
Phil Eaton provides a basic introduction to setting up and working with a three-node EDB Postgres Distributed (PGD) cluster on AWS using PGD 6’s new CLI.
https://www.enterprisedb.com/blog/simple-clustering-and-replication-solution-postgres
AI Agent Development and Optimization Series (Part 1): Creating First Agent

Finnick Huo shows how to build a simple agent in Python with LangChain.
Securing Your Data: A Deep Dive into Data Masking
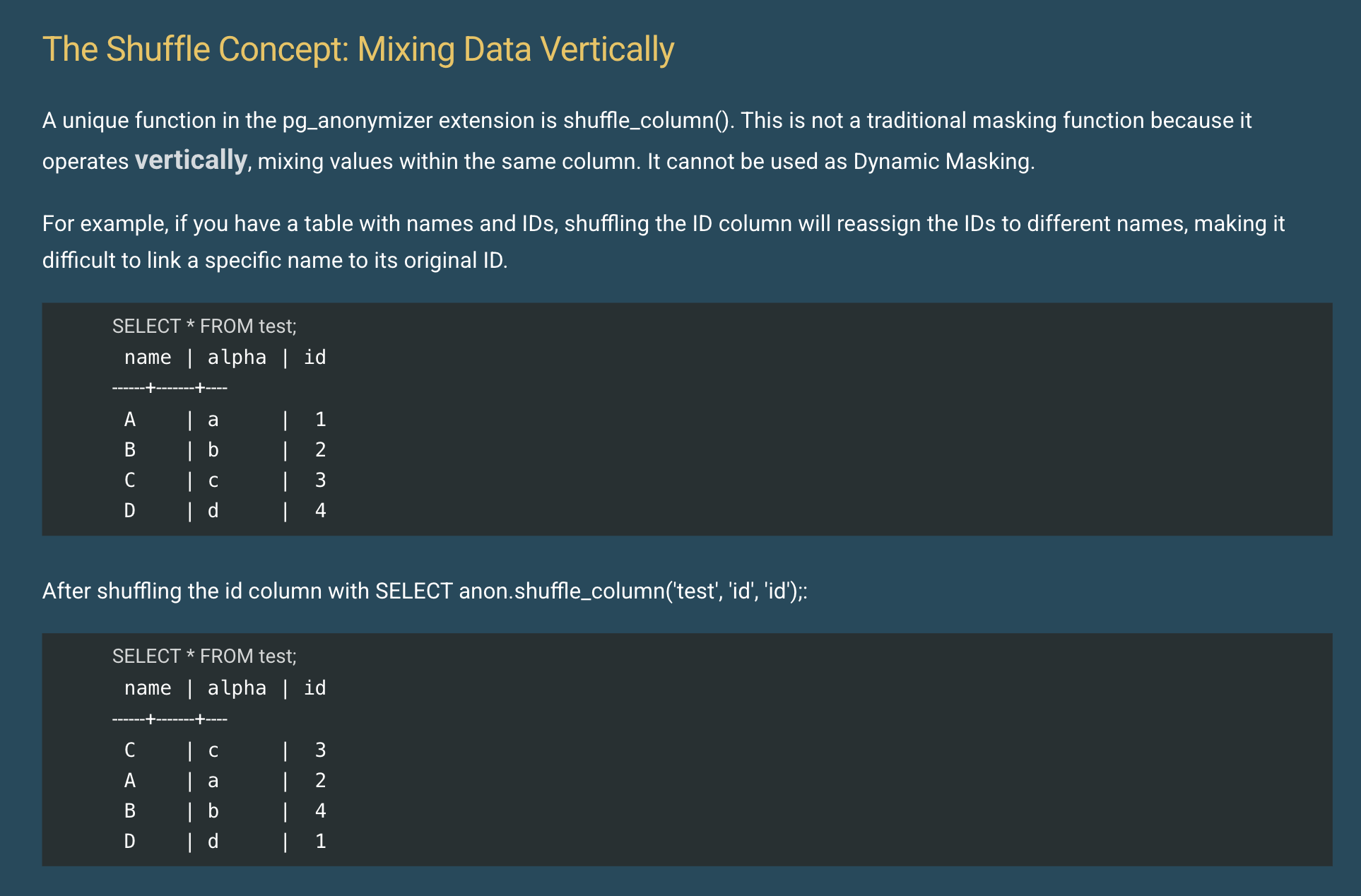
Nishant Sharma explores the pg_anonymizer extension for masking PostgreSQL data.
By using the declarative approach of the pg_anonymizer extension, organizations can build privacy directly into their database design, ensuring compliance and security across their development, testing, and production environments.
https://www.enterprisedb.com/blog/securing-your-data-deep-dive-data-masking
Building MCP Servers from Protobuf

Charlie Zhang published parts 2 and 3 to his 4-part series on building an MCP server.
CNPG Recipe 22 - Leveraging the New Supply Chain and Image Catalogs

Gabriele Bartolini writes about new approaches to building images for CloudNativePG.
PGDay Lowlands Debates
Jonathan Battiato participated in a debate (above) on running PostgreSQL on Kubernetes at PGDay Lowlands, assuring the community that PostgreSQL is safe to run on Kubernetes.
Gianni Ciolli also participated in a debate (below) on auto-tuning PostgreSQL configuration where he highly encouraged the practice.
https://www.postgresql.eu/events/pgdaynl2025/schedule/session/6808-debate-kubernetes/
Until next time
We hope you enjoyed this edition of the EDB Engineering Newsletter! Consider joining the PostgreSQL Hacker Mentoring Discord or the CloudNativePG Slack to get involved!
The EDB Engineering Team

The EDB team at PGConf.Brasil in early September 2025.